A supervised learning algorithm takes in both a known set of input data and corresponding output data. It then trains a model to map inputs to outputs so it can predict the response to any new set of input data.
As we’ve previously discussed, all supervised learning techniques take the form of either classification or regression.
Classification techniques predict discrete responses. Use these techniques if the outputs you want to predict can be separated into different groups.
Examples of classification problems include medical imaging, speech recognition, and credit scoring.
Regression techniques, on the other hand, predict continuous responses.
A good example of this is any application where the output you're predicting can take any value in a certain range, like stock prices and acoustic signal processing.
Now, say you have a classification problem you’re trying to solve. Let's take a brief look at just a few classification algorithms you could use.
The Logistic Regression algorithm is one of the simplest. It is used with binary classification problems, meaning problems where there are only 2 possible outputs. It works best when the data can be well-separated by a single, linear boundary. You can also use it as a baseline for comparison against more complex classification methods.
Bagged and Boosted Decision Trees combine individual decision trees, which have less predictive power, into an ensemble of many trees, which has greater predictive power.
It is best used when predictors are discrete or behave nonlinearly, and when you have more time to train a model.
Keep in mind there are many other classification algorithms; these are just two of the most common.
There are plenty of algorithms to choose from if you have a regression problem as well.
Linear regression is a statistical modeling technique. Use it when you need an algorithm that is easy to interpret and fast to fit, or as a baseline for evaluating other, more complex, regression models.
Nonlinear regression helps describe more complex relationships in data. Use it when data has strong nonlinear trends and cannot be easily transformed into a linear space.
Again, these are just two common regression algorithms you can choose from; there are many more you might want to consider.
Now let’s put it all together and see how this process might look in the real world.
Say you’re an engineer at a plastic production plant. The plant’s 900 workers operate 24 hours a day, 365 days a year.
To make sure you catch machine failures before they happen, you need to develop a health monitoring and predictive maintenance application that uses advanced machine learning algorithms to classify potential issues.
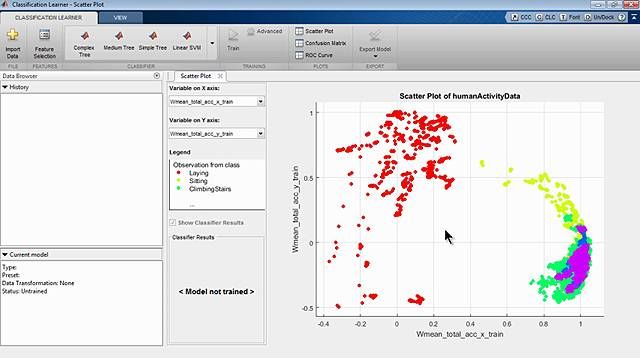
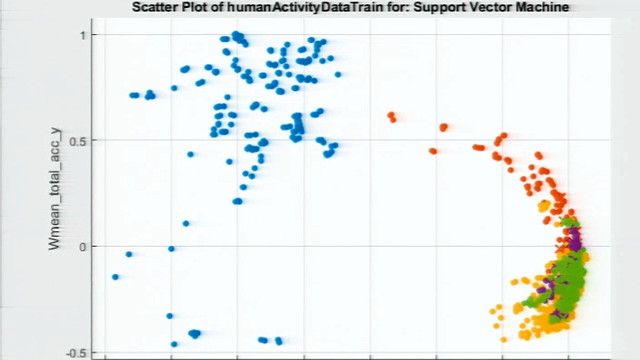
After collecting, cleaning, and logging data from the machines in the plant, your team evaluates several classification techniques. For each technique, the team trains a classification model using the machine data, and then tests the model’s ability to predict if a machine is about to have a problem.
The tests show that an ensemble of bagged decision trees is the most accurate. So, that’s what your team moves forward with when developing the predictive maintenance application.
In addition to trying different types of models, there are many ways to further increase your model’s predictive power. Let's briefly talk about just three of these methods…
The first is feature selection, where you identify the most relevant inputs from the data that provide the best predictive power. Remember: a model can only be as good as the features you use to train it.
Second, feature transformation is a form of dimensionality reduction, which we discussed in the previous video. Here are the 3 most commonly used techniques.
With feature transformation, you reduce the complexity of your data, which can make it much easier to represent and analyze.
Hyperparameter tuning is a third way to increase your model’s accuracy. It is an iterative process where your goal is to find the best possible settings for how to train the model. You retrain your model many times using different settings, until you discover the combination of settings that results in the most accurate model.
So that’s a quick look at supervised learning. In our next video, we’re going to take a deeper look at an example machine learning workflow.
Until then, be sure to check out the description below for more helpful machine learning resources and links. Thanks for watching.