Machine Learning Made Easy
Machine learning is ubiquitous. From medical diagnosis, speech, and handwriting recognition to automated trading and movie recommendations, machine learning techniques are being used to make critical business and life decisions every moment of the day. Each machine learning problem is unique, so it can be challenging to manage raw data, identify key features that impact your model, train multiple models, and perform model assessments.
In this session we explore the fundamentals of machine learning using MATLAB. Through several examples we review typical workflows for both supervised learning (classification) and unsupervised learning (clustering).
Highlights include
- Accessing, exploring, analyzing, and visualizing data in MATLAB
- Using the Classification Learner app and functions in the Statistics and Machine Learning Toolbox to perform common machine learning tasks such as:
- Feature selection and feature transformation
- Specifying cross-validation schemes
- Training a range of classification models, including support vector machines (SVMs), boosted and bagged decision trees, k-nearest neighbor, and discriminant analysis
- Performing model assessment and model comparisons using confusion matrices and ROC curves to help choose the best model for your data
- Integrating trained models into applications such as computer vision, signal processing, and data analytics.
About the Presenter: Shashank Prasanna is a product marketing manager at bat365, where he focuses on MATLAB and add-on products for statistics, machine learning, and data analytics. Prior to joining bat365, Shashank worked on software design and development at Oracle. Shashank holds an M.S. in electrical engineering from Arizona State University.
Recorded: 19 Mar 2015
Hello, and welcome to Machine Learning Made Easy. My name is Shashank Prasanna. I'm the product manager for statistics and machine learning products at bat365.
Here's the agenda for the rest of today's presentation. I'll start off with a high-level overview of what machine learning is and why you might want to consider it. We'll then see some key challenges in machine learning.
Next, I'll take a deeper dive into machine learning by solving an interesting problem that involves real-world data. To tackle this problem, I'll introduce a typical workflow that often gets used in solving machine learning problems. We'll then go through another interesting example that involves image data. I'll show you a live demonstration that uses video from a webcam to identify objects. We'll wrap the session up with a summary and some guidance on when to consider machine learning.
Since this is a Made Easy topic, there are no prerequisites. Basic familiarity with MATLAB is helpful, but not required. Machine learning is ubiquitous. These techniques are increasingly being used in today's world to make critical business and life decisions. Today, with machine learning, we are able to solve problems in automotive, finance, computer vision, and several other fields that were previously considered impossible.
So what is machine learning? Let's take a minute to quickly go over the high-level concepts of machine learning. Even if you're familiar with this topic, this should serve as a quick reminder of when it is actually useful to pursue machine learning.
We can define machine learning as a technique that uses data and produces a program to perform a task. Let me explain that in the context of an example. Consider a task that involves using sensor data from a mobile phone to detect a person's activity; for example, if the person is walking, sitting, standing, and so on. The standard approach to solving such a task is to either analyze the signal and write down a program with a set of well-designed rules, or you may know a priori a set of equations or a formula that uses the inputs and predicts the output.
The machine learning approach is to learn such a program directly from data. In this case, we provide the algorithm with input and output data and have it learn the program to solve this task. This step is often referred to as training. The output is a model that can now be used to detect activity from new sensor data.
Notice I don't explicitly mention a specific machine learning algorithm because there are plenty of algorithms to choose from, and each have their own strengths and weaknesses. We'll see that when we go through this particular example in detail. If there are two things I'd like for you to take away from this slide, that would be, one, you need data. If you don't have data, you can't do machine learning. This is a strong requirement.
Two, consider machine learning only when the task is complex, and there is no magic equation or formula to solve it. If you have a formula, you can go ahead and implement it. Machine learning will work, but it's not recommended approach in such a situation.
So let's go to MATLAB and take a look at what the machine learning approach looks like. The data we are working with consists of six inputs, three from the accelerometer and three from gyroscope of a mobile phone. The response, or the output, are the activities performed. These include walking, standing, running, climbing stairs, and laying.
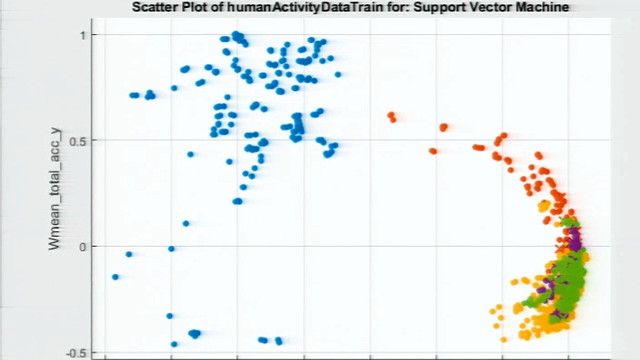
This is Classification Learner. It's an interactive tool that lets you perform common machine learning tasks, such as interactively exploring your data, selecting features, specifying validation schemes, training models, and assessing results. On my left here, I have several different machine learning models that have already been trained on sensor data. Right next to each model is a percentage number that indicates the accuracy of the selected classifier on a separate validation set. I can use the visualization on the right here to explore my data to search for patterns and trends.
Training a new model is easy. I simply navigate to the Classifier gallery, choose a classifier of interest, and then hit Train. Once training is complete, you can see the new model in the History List along with the model's performance accuracy. The higher this number, the better the model may perform on new data. I will choose my best-performing model and click Export to start using my model in MATLAB, and I can see that the exported model is right here in the workspace.
I'd now like to use this model, along with some test data, to visualize the model's prediction results. This is a plot that shows two and a half seconds of streaming accelerometer and gyroscope data. The green bar here on the top is showing the actual activity the person was performing corresponding to the sensor signal right here. The bottom bar is green if the model is able to successfully predict the actual activity of the person, and it's red if it is—if it fails to predict the actual activity. You see that the model often gets confused between walking and climbing stairs.
Let's quickly recap what we just achieved. We use data to fit several different models using Classification Learner. We then chose the one that showed good results, and we tested it to make sure it was doing what it was supposed to. That seemed quite simple, so why does machine learning have a reputation for being so hard?
To answer that question, I'd like to use a quote from a famous statistician, who once wrote in a textbook, "All models are wrong, but some are useful." Why? Because models are approximations. Not just machine learning models—all models are approximations based on several assumptions, but that doesn't make them any less useful. Machine learning models can explain complex patterns in data, but to apply machine learning successfully, you need to find useful models, and that can be a challenging task.
In reality, there's not one, but several challenges in every step of the machine learning workflow. Data comes in all shapes and sizes. It could be simple numeric data, such as from financial data feeds or sensor signals, or could be streaming images from a camera or text data. Real-world datasets are usually messy, and not always tabular.
Pre-processing data requires domain-specific algorithms and tools. For example, signal or image processing algorithms are required to extract useful features from signal and image data. Statistics algorithms are required for feature selection and feature transformation. We often require tools from multiple domains, and when working with multiple machine learning algorithms, searching for the best model can be a daunting and time-consuming task.
At the heart of it, choosing the best machine learning model is a balancing act. Highly flexible models may be accurate but may also overfit your data and perform poorly on new data. At the other extreme, simple models may assume too much about the data. There's always a tradeoff between speed, accuracy, and complexity of the model.
Finally, machine learning workflows are never a convenient linear workflow. We always constantly have to go back and forth, iterate, and try different ideas before we converge onto a solution. My goal today: introduce you to a common set of tools and strategies to address these challenges.
Here's a simple two-step workflow we like to follow in solving a machine learning task. The first step is to train your model. We start by bringing in a data, which would come from a variety of different sources, such as databases, streaming devices, and so on. Next, we pre-process the data using feature extraction or other statistical tools. This step is critical to transform your data into a format that machine learning algorithm can work with.
After that, we are ready to learn from data. If the task is to predict labels or categories, we choose classification methods. If the task is to predict continuous values, then we choose regression methods, and then we go ahead and build a model. This, of course, is an iterative process that requires going back and forth to the pre-processing step, trying different machine learning algorithms, tweaking different parameters, and so on.
The second step of this workflow is to actually use the model, so on the left, I have new data, and on the right, I need to make predictions. So what do we need to go from data to predictions? First, we need to use all the pre-processing steps for the new data, so there's no additional work involved here. We just reuse all the hard work we spent during the training phase.
Next, we use a model from the training phase and make predictions. For several engineering problems, the second step is often deployed or integrated into production environments, like for example, onto a server executing automated traits using machine learning. Let's now use this workflow to go through an example in MATLAB.
The object of this example is to train a classifier to automatically identify human activities based on sensor measurements. The data consists of six inputs, three from accelerometer and three from gyroscope. The response of the output are the activities performed: walking, standing, running, climbing stairs, and laying.
The approach we'll take is as follows. First, we'll extract basic features from sensors signals. We'll then use Classification Learner to train and compare several different Classifiers and, finally, test the results on unseen sensor data.
So this is MATLAB. We'll start with the current folder window here. Since the first step of the workflow is to bring in data, I'm going to load some raw sensor data I have here in a MAT file. To import this data, all I have to do is pretty much drag and drop it into the workspace window. The workspace window helps you keep track of all the variables in MATLAB, whether they're existing variables or new variables that we create as we move along.
My data consists of seven variables. The first six are sensory input variables, three for gyroscope and three for accelerometer x, y, and z. The last variable, TrainActivity, contains the activity labels for each observations of the sensor measurements. Notice all the variables have around 7,000 observations. Let's take a look at what an individual sensory input looks like.
If I plot a single row of the x-axis gyroscope data, we see that it has around 128 points. Now, this is what the data represents. Sensor data are often collected and fixed with frames of windows. Each row, with 128 readings, corresponds to two and a half seconds of sensor data.
Now, this data is not in a form that can be used for machine learning. I must first process all these inputs to extract features for each of these 128 points or two-and-a-half-second windows, and I have to do this for all six sensor inputs. But before we start with the feature extraction, let's take a look at what the raw sensor data looks like.
I have a custom plot here that shows three accelerometer raw sensor data, and they have different colors corresponding to the activity the person was performing. Plots in MATLAB are fairly interactive. I can zoom in to see if there are any visual patterns or if there are trends that can help us identify the activity of the person.
At a quick glance, we can see that the sensor values look different for each of these colors. For example, the orange values here, which correspond to climbing stairs, is quite different from the purple values, which correspond to standing. However, at the same time, it's hard to visually differentiate walking and climbing because both involve a lot of motion. Problems such as these are good candidates for machine learning, as it's not always obvious that we can define rules for each of these activities.
Before we start with the feature extraction step, I'm going to create a single table from these six sensor inputs. Tables are excellent tools for holding mixed-type data, which is common in machine learning. In this example, we have sensor measurements, which are numeric, and labels which are categorical values.
I now have a single table variable in my workspace that includes all the six individual sensor variables. Another advantage to using tables for machine learning is that I can apply a single feature extraction function to all the variables in this table with a single line of code. All I have to do is call VarFun, which stands for Variable Function, and pass in my feature extraction function. WMean here is a function that computes the average value of each row in the sensor variable. In this case, I am computing the average of two-and-a-half-second frame of sensor values.
WMean is a function in my current folder browser, and as you can see, it's a fairly simple function. But depending on your application and the features you want to extract, this could be as sophisticated as you please. In addition to the mean, I'd like to extract two other features, which is a standard deviation for each frame, and PCA, which stands for a principal component analysis, and I'd like to retain only the first principal component. Since tables can hold mixed-type data, I'm going to assign the label Activities as a new variable called Activity Within Table.
Let's run the section and take a look at what the human activity data table looks like. I have a total of 19 columns, and the first six correspond to the average value of the frame. The next six are the standard deviation of the frame, and the final six are the PCA outputs. My last column is the activity corresponding to each observation, which could be laying, sitting, climbing stairs, standing, or walking.
Now that we have a data ready, let's move the Classification Learner to train our models. Classification Learner is part of the Statistics and Machine Learning Toolbox, and you can launch it by typing Classification Learner on the MATLAB command line. Or you can find it under the AppStat under MAT Statistics and Optimization.
We first start by importing our data from the MATLAB workspace. Under step one of the import dialog box, we choose our dataset from the MATLAB workspace. Under step two, notice that the app automatically selects if a variable is a predictor or a response.
The app decides this based on the data type. However, you can also choose to change its role or completely remove the variable. For now, we leave this as it is.
Under step three, we can choose our validation method. Validation protects against problems like overfitting. Choose Cross Validation when you have a relatively smaller size dataset, as it makes efficient use of all the data. Choose Hold Out if you have sufficient data.
I'm going to choose this option for our problem since we have a lot of data points. Setting my Hold Out percentage to 20% instructs the app to use 80% of the data for training and 20% for validation of the model's performance. The last option is not usually recommended. Since all the data is used for training as well as testing, this leads to a biased estimate of the model's accuracy.
Classification Learner is a fairly interactive environment with a number of different windows and components, and I promise we'll go through every single one of them as and when they become relevant. The toolstrip on the top shows a left-to-right workflow all the way from importing your data to exporting your model. At the center here is pairwise scatter plot grouped by the response variable.
This plot can be useful for finding patterns. For example, this pair of predictors, we noticed that laying appears to be well separated from the rest of the activities. Sitting also appears to be well separated, but there is some overlap. The feature selection option on the toolstrip allows you to exclude predictors from the model. For this example, since we don't have too many predictors, we're going to leave this as it is.
When solving classification problems, there is no one size fits all. Different classifiers work best for different types of data and problems. Classification Learner lets you choose from decision trees, support vector machines, nearest neighbors, and ensemble classifiers, and for each classifier type, there are several presets that are excellent starting points for a range of classification problems. If you're not sure which to choose, a pop-up tool tip gives you a brief description of the classifier.
When working with MATLAB, help is always just a click away. For further assistance, simply click on the question mark on the top right, and this opens up the documentation for the app. You'll find all the information you need about the app right here. For now, let's go to the following section that has guidance on choosing a classifier.
Here's a nice table that gives you guidance on which classifier to choose, depending on the tradeoff you want to make. For example, decision trees are fast to fit, but have a medium predictive accuracy. On the other hand, nearest neighbors have high prediction accuracy for smaller problems, but also have high memory usage. Let's use this tip from the documentation and start with the decision tree first.
Training a model is easy. Simply choose a preset from the gallery and hit train, and this will produce a train model in the model history, along with its prediction accuracy. Let's also train a medium tree and a complex tree. The model that performs best on the validation set is always shown by a green box.
In addition to the prediction accuracy percentage, there are other diagnostic tools that are useful. Confusion matrix is a great tool that can tell you how a classifier's performing at a quick glance, so this is how you read a confusion matrix. Anything on the diagonal is correctly classified. Anything off diagonals have been misclassified. A perfect classifier would have 100% on the diagonal and 0% everywhere else.
Let's take a closer look at one activity: climbing stairs. The way to read this is 89.1% of the time, the model successfully predicted the activity. However, 10.9% of the time, the model thought that climbing stairs was walking, or in other words, the model misclassified climbing stairs as walking. We can always switch between different models in the modern history to compare confusion matrices.
Another diagnostic tool that's available in the app is the Auto C Curve. Auto C curves are used to describe the sensitivity of a binary classifier. The shape of the curve shows a tradeoff between sensitivity and specificity. As we move upward and to the right of the curve, we increase the chance of true positives, but also increase the chance of false positives.
In my opinion, one of the greatest advantages of using apps instead of writing code is the ability to train multiple models. In addition to decision trees, I'm now going to train nearest neighbor classifiers because I know they're fast to train and fast to predict. When training multiple models, you don't have to be confined to these presets.
If you are an advanced user, you can always bring up the advanced pop-up to tweak the classifier parameters. These changes are also shown in the model history for convenience. We now have about eight models or so in the model history, and I train all of them in a matter of seconds without writing a single line of MATLAB code.
There are two modes in which you can export your analysis. You can either export your model directly into MATLAB, or you can choose to generate MATLAB code that lets you automate all the steps we took in building this model without having to write any code. Let me choose this option to show you what the generated code looks like.
What I have here in MATLAB is a well-commented, completely autogenerated MATLAB code. We can also see the different steps in a workflow captured by the code. For example, extracting predictors and response, training a classifier using the KNN classifier, and setting a Hold Out validation and so on. You can always customize this generated code to integrate it into your applications.
Let's go back to Classification Learner and export a model instead, and we can see that the model is now available in the MATLAB workspace. We are now ready to test the model on new data. First, we load in some new sensor data from a MAT file. We then apply the same feature extraction steps from before. We then use the exported model to test results on this new sensor data.
As we saw before, the top green bar shows the actual activity the person was performing, and the bottom green bar, when the model successfully detects the activity. And it is red if it makes a mistake. If you want to try a new model, you can simply go back to Classification Learner and either export the model directly or generate MATLAB code and train new models to predict with new data.
Let's take a quick look at our workflow to summarize what we just did. Our training data was sensor signals obtained from mobile phone sensor. We applied basic pre-processing techniques to extract features like average standard deviation and PCA. We then used the Classification Learner app to arrive at our best model based on the holdout validation accuracy.
For prediction with new data, we applied the same pre-processing steps on new data, and then we used a trained model to make predictions and then visualize the results. Let's go through another example, where we'll train a machine learning model using image data. The objective of this example is to train a classifier to automatically detect cars from webcam video. The data consists of several images of four different toy cars. The response of the output is a label for each of these four cars.
The approach we'll take is as follows. First, we'll extract features from these images using a technique called bag-of-words. We then use these features to train and classify several different classifiers using Classification Learner. And finally—this is the interesting part—we'll see a live demonstration of the model we trained identifying cars in real time from a webcam feed in my office.
So let's switch to MATLAB. I'm going to clear out my workspace and start clean slate. So let's take a look at our data. So here are a bunch of images and folders, and each folder name is the label for the set of images in that folder. Let's take a look at what the images look like outside of MATLAB.
So here are a bunch of images for sand dune taken from several different angles and varying lighting conditions, and I have several such images for all the four cars. When working with images, loading all the images in a loop and keeping track of all the files and folders and the labels can be painful. The Computer Vision System Toolbox has convenient tools like Image Set that makes this task easy. I simply provide Image Set with a folder that has all my images and instructed to look at all the sub folders as well. Another important advantage of Image Set is that it doesn't load all the images to memory, so it's easy to work with when you have lots and lots of images.
To pre-process my data and to extract features, I'm going to use an approach called bag-of-features. This is a fairly sophisticated technique to do feature extraction from images and works particularly well. If you are interested in learning more about what the function does, the Computer Vision System Toolbox documentation has detailed explanation on what the algorithm does underneath the hood. For now, let's treat this function as a feature extraction tool that we'll use to extract features from images.
Like we did in the previous example, let's create a table and assign the labels to the table. Let's jump right into Classification Learner and start training our model. Let's take a quick look at our data. We have 200 new extracted features from the images, and the last variable is the response. I'll again choose holdout as my validation, and I'm now ready to start training models.
I'm going to train few models quickly, starting with nearest neighbors and support vector machines. Now that I have a few more or less trained, let's do a quick visual diagnostics using the confusion matrix. The confusion matrix is mostly diagonal, so that's a good thing, and we'll quickly export one of these models and see how it performs on real streaming images.
Before I run this function, I'd like to show you the code and how easy it is to obtain streaming images and classify them in real time. The function takes in two inputs. First is the train model, and the second is a bag-of-features object, which I will use to extract features from new images.
Starting a webcam is easy. All I need to do is call the Webcam command. Inside a continuously running loop, first, I obtain a snapshot from the webcam and then convert it to grayscale, which means the model should be able to identify cars without the color information. The next step is to extract the features from this new image, and finally, use a predict function and the trained model to make predictions on the new image. Let's go back and run this function.
The top plot here shows images from my webcam, and the green bar here is the result of the model making predictions on this image. This is the classifier I'm using, and this bar chart shows how confident the classifier is that this car belongs to either Lightning, Mater, Nigel, or Sand Dune. So let's move the camera around to see how the model performs at different angles and orientation.
So the model mostly gets Lightning right, but as we move to Nigel, you'll see that the model is not completely confident which car it is. The probability plot on the bottom shows you how confident the model is in predicting which car this is. This is Sand Dune, and finally Mater.
Let's export another model from Classification Learner and see how two models perform side by side. So I'm going to use Linear SVM and choose Export with a default name. So I now have two classifiers, or two models in my workspace. One is KNN. The other is support vector machines.
Now let me run this piece of code which compares the performance of these two classifiers side by side. What we again see here is a video comparing the performance of two classifiers side by side. On the top left in red is a performance of our SVM classifier, and on the bottom right is the performance of KNN classifier. The important thing to note here is not only is it easy to compare and test models in Classification Learner, but it is just as easy to export these models to MATLAB and test them in real time.
That brings us to the end of this demonstration. Let's now switch back to our presentation. Let's again summarize what we just accomplished using our familiar workflow diagram.
Our inputs consisted of several labeled images on disk. We use the bag-of-words approach to generate new features. We then use the Classification Learner app to arrive at our best model. For prediction step, we obtain new data from a webcam, encoded the images and new features, and use a trained model to make real-time predictions.
This brings us to the summary and key takeaways. To summarize what we've seen so far, let me go back to the challenges I've set up at the beginning of this presentation. Hopefully, you've seen today how MATLAB is able to address these challenges.
For the first challenge of data diversity, we saw how MATLAB can work with different types of data. MATLAB can also access and download financial data feeds, work with text, geospatial data, and several other data formats. MATLAB also has libraries of vetted industry standard algorithms and functions. MATLAB also offers additional tools for specific engineering workflows in finance, signal processing, image processing, and several others.
We also saw how we could quickly build and prototype solutions, which interact to app-driven workflows that let you focus on machine learning, not programming and debugging. Best practices for machine learning, such as cross validation and model assessment tools, are integrated into apps and functions. As we saw, MATLAB also has rich documentation that has several guidelines that help you choose the right tools for the job. Finally, MATLAB is inherently a flexible modeling environment and a complete programming language with no restrictions to the customizations you can make to your analysis. This makes MATLAB an excellent platform for machine learning.
This brings us to the end of our presentation, and I'll try to keep this short and brief. I'd like to share with you some guidelines on when you should consider machine learning. Consider machine learning if you're working on a problem where handwritten rules and equations are too complex or impossible to formulate. Or when the rules of your task are constantly changing, and your program or model needs to constantly adapt since your task is a moving target. Or when the nature of your data changes, and the program needs to constantly adapt.
And hopefully, I've been able to convince you that MATLAB is a powerful platform for every step of the machine learning workflow. We're always interested in hearing from you, and you can find my contact information on the Statistics and Machine Learning Toolbox product page. If you're interested in learning more, please take a look at the product documentation. There are plenty of examples and concept pages that can not only help you get started, but also guide you as you master the tools.
To learn more about algorithms, application areas, examples, and webinars related to machine learning, feel free to visit the Machine Learning page. This brings us to the end of this session. Thank you all for listening.
Download Code and Files
Related Products
Learn More

Featured Product
Statistics and Machine Learning Toolbox

Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: .
You can also select a web site from the following list
How to Get Best Site Performance
Select the China site (in Chinese or English) for best site performance. Other bat365 country sites are not optimized for visits from your location.
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)