In the last video, I showed how I built a high five counter by retraining an existing deep neural network. I went from basically nothing to something that runs in about 2 hours, which is pretty awesome!
But, simply getting a model that can classify your data isn’t the end of the deep learning workflow. Some other things that we need to consider are that the trained network is usually part of a larger system and we want to be able to incorporate it into the complete design. We also want to have some amount of confidence that the model will work on unseen data and that it’s going to interact as expected with the other system components. And ultimately we want to deploy it onto a target device which requires certain performance characteristics. And each of these require additional work and considerations beyond what I did in the last video. And so that’s what we’re going to talk about now. I hope you stick around for it. I’m Brian and welcome to a MATLAB, Tech Talk.
We can sum up this video with a question. I have a trained network, what’s next? And before we get into it, I want to reiterate my usual caveat that this video isn’t intended to cover everything. I just want to introduce some concepts and get you thinking about the overall problem. I’ve left links in the description to resources that go into far more depth on all of this.
Alright, let’s get to it.
At the end of the last video, we were left with a GoogleNet model that was retrained to recognize two patterns, it’s looking for these pink volcanoes and classifying them as high-fives and anything else we send through the network gets classified as no-high-fives. So, what’s next? Well, I think it’s reasonable to want to know whether the network works or not. Now, we know it works in some fashion because during the training process it was using 40 validation images to assess the model accuracy, and it only mislabeled one out of the 40.
This is great for sure, but there are two things I want to point out. The first is that even though we have some confidence that this model works for the 40 validation images, we don’t necessarily know that it works on images that haven’t been seen yet. Now if the 40 validation images did a great job of covering the entire solution space, then we could be confident that the network will only come across situations that are similar to one of these images. However, in this case, 40 images was enough to gain confidence for the video I was making but I don’t think it was enough to cover all of the possible arm motions the network might see in real life and so we’re going to want to do some additional testing if we’re going to deploy this network into the field.
The second thing I want to point out with this model is that we validated it with scalogram images that are uncorrelated to each other. What I mean is that each one comes from its own stand alone arm motion, but that’s not quite the case with how I’m using this network. Remember, I’m looking to pass in essentially a continuous stream of scalograms and I want to count the number of high fives in my data. That means that as the data streaks across the window, I’m going to pass in multiple frames with the same high five in it, and my network is going to return a high five label several times in a row. And due to the errors in the network - the 1 out 40 that it misses - some of these frames will be mislabeled. Both of those things will cause my counter to be off if I just assume each scalogram that is labeled a high five is actually it’s own unique motion.
So, the neural network is just part of the overall logic that I need for my counter. And this is almost certainly the case for all deep neural network solutions. You’re going to develop a model that can classify data and you obviously want to know that that works, but beyond that there is other logic that makes that network an actual product and it’s important that the system as a whole works as well.
Now, my project was rather simple and the stakes were pretty low if it didn’t function correctly, but let me walk through the way I approached building out the rest of the high five counting logic. I built a MATLAB script that would read the acceleration data and keep the most current 1.4 seconds of data in a buffer. Then every third sample time, preprocess the buffered data into a scalogram, make sure there are no pixel values greater than one, then run it through the trained network with the classify function. Then I only count a new high five if it has been more than 1.4 seconds since the last high five. This is how I ensured that I only counted each high five a single time since it will have completely left the buffer before I look for a new one. I did this in MATLAB because I only needed a few lines of code for this project, but this whole thing could have been developed in Simulink as well.
In fact, here is the Simulink version of my high five counter. Well, it’s almost exactly the same. The difference is that rather than read the accelerometer live, I’ve opted to just read in a 5 second acceleration profile that I saved off earlier. The idea being that I could collect several of these 5-second snippets where I know exactly how many high fives are in that data and then use them in regression test whenever I update the network or the other logic.
Other than that, the rest of this logic is doing the same thing. I’m updating the acceleration buffer, preprocessing it into a scalogram, classifying it with my trained network, and then counting the number of high fives. Let’s open the scope and run it so you can see it in action.
The top graph is showing the read in acceleration profile which has a single high five, right at the beginning. The counter only registers a single high five, as expected even though you can see that several scalograms were labeled as high fives as that pink volcano was streaking across the image. The other thing to note is this delay between the actual high five and when it was counted. This is due to the fact that my network was trained to recognize the high five when it was in the middle of the image, or about a few tenths of a second after it occurred.
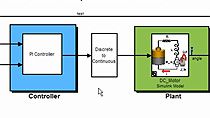
Ok, what’s nice about Simulink, is that I can now package this logic into its own subsystem and can use it as part of an even larger system. Like for example, this model shows the implementation of a multi-loop PI controller acting on a robotic arm. Maybe if I was so inclined, I could use my new subsystem to determine if this robotic arm ever made a motion that looked like a high five. And, once I was happy with this implementation, I could use Simulink coder to build embedded C code and deploy all of this logic including my deep neural network to the arm itself.
Now I’m not actually going to build this out any further because I’m just making a video to demonstrate a few things, but if I did want to keep going on this project my next steps would be to systematically try all of the different arm motions I could think of, both high five and non-high five motions. And I’d probably even have other people try it out, and from cultures that might high five differently. And every instance where the user motion was misclassified by the system I would save off that data and add it to my training data set to retrain and refine the network.
Now in this way, I’m never guaranteed to have a perfectly functioning network, but I’m increasing the solution space over which I’m confident that it will perform. And this is a standard approach for deep neural networks. We don’t yet have a good systematic way to verify them, so we rely on these sampling methods like Monte Carlo approaches to gain confidence in the network over the entire solution space. And this is more than likely going to be the case for your project as well, whether you’re looking for material defects, picking out verbal commands in audio, or classifying RF modulation schemes. You’re going to integrate the trained neural network into your full system and test it in a variety of situations.
But as you can see, no matter how many different tests I run, there will always be sections of the solution space that haven’t been tested.
And so, this is where synthesized data can be so powerful. Remember in the 2nd video where we synthesized RF data, and the idea was that we would use it for training a network? Well, now we can use it to generate millions of different test cases and produce a really dense sampling of the solution space. Which would give us just a huge amount of confidence in the system - you know as long as the synthesized data reflected reality. Now, I can’t really do that with my high five project because I don’t have a good understanding of the acceleration patterns that are possible with high fives and therefore can’t easily synthesize it. For my project it was easier to physically test it rather than synthesize the test data.
But regardless of whether you can synthesize test data or not, you’re going to want to ultimate test the system in the real world on the real hardware. Which brings me to the other thing I wanted to talk about which is deploying your network and other code to a target computer.
Deployment is important because it doesn’t matter if your code works, if it doesn’t work on the hardware it’s supposed to run on. There’s a bunch of good information that I linked to in the description on generating optimized code for deep learning networks directly from MATLAB and Simulink for embedded GPUs, CPUs, and FPGAs. So, I’m not going to go through that here. Instead, I want to take the last few minutes to talk specifically about the size and speed of the trained network.
For a high five counter that’s going to be deployed to an embedded CPU on a watch, it’s important that the size of the network is taken into account. I started from GoogleNet, which if I open up the Deep Network Designer I can quickly get a sense of the size of this network. This neural network has 7 million parameters. Which is pretty massive for a simple high five counting program.
If memory space or execution speed is a concern, then I’m going to have to find a way to make this smaller. There are a few options. For one, I could just start from a smaller pretrained network - something like Squeezenet, which only has just over 1 million parameters and then again use transfer learning to retrain it for high fives. The idea would be that maybe I don’t need the accuracy or feature details that the larger GoogleNet provides. Here, I did the same transfer learning steps that we took in the last video and retrained Squeezenet. And at least for these particular parameters this network is 90% accurate. So, a little less accurate than GoogleNet. Now I can export the re-trained SqueezeNet to the workspace and run it in my MATLAB or Simulink simulation. But check this out, we can see that this million parameter network is still about 3 megaBytes.
Now, if this size is still a problem, instead of finding an even smaller pertained network, I could also try reducing the size of my network by pruning it or quantizing it. Pruning is removing some of the parameters in the network that don’t contribute much to classifying your particular data. And quantizing means taking the single or double precision weights and biases in your network and quantizing them to 8-bit scaled integer data types. The idea is that we can still get the same performance from the network without having to use high precision data types.
Just to give you a sense of what reducing the network could look like in one instance, let me show you the result of quantizing my trained network. I’m using the deep network quantizer app to pull in my trained model, and quantize it to 8-bit scaled integers. This took a few minutes which I’m skipping over, but the important metric here is that the network was compressed by 75% and it had no measurable impact on its accuracy.
So, it has the same number of parameters, but it’s one quarter the memory size. In addition to this, I could also try pruning the network to reduce the number of parameters in a way that also doesn’t impact accuracy but I’m going to leave this model as is for now.
Hopefully, you can see that with a pretrained network, transfer learning, pruning, and quantizing you might be able to get to a model that is sufficient size and efficiency for your application.
But if you can’t, then the last option is to build your own network architecture from scratch. This option requires the most training data and the most training time since at the beginning the network has no concept of anything, and so it has to learn everything.
The other downside is that it takes a good understanding of different network architectures to create an efficient one from scratch. But, this is where tradeoffs can occur. How much specialized development do you need to do from scratch versus how efficient and fast do you need your architecture to be.
My high five counter might benefit from a smaller and specialized architecture since it has to be deployed to an embedded processor on a watch, whereas, a system that is looking for material defects could run on a dedicated desktop computer with a GPU. And it might not even need to run realtime if getting instantaneous results back is not necessary.
So, I guess the thing I want you to take away from this is that there are things that you need to consider with deep learning. Some of those things are How deep does the network need to be in order to be able to find and classify the patterns in your data? Can you get by with a pertained network and transfer learning? How are you going to access labeled training data, and how will you ensure that the data covers the entire solution space? In general you will need more training data to train larger networks, and to train networks from scratch. And how are you going to gain confidence in your network and in the system as a whole? Can you synthesize data, and can you run simulations, or does all testing need to be done in the field?
There is no one answer for every project, but hopefully, you can start to see the benefits and possibilities for deep learning. Perhaps you have an engineering problem you’re working right now where the solution comes down to being able to detect and label complex patterns in data. If so, deep learning is an approach that you might want to consider as part of your trade studies. It might be easier than you think.
That’s where I’m going to leave this video for now. Don’t forget to check out the resources that I left in the description of this video. There’s a lot of good stuff there. If you don’t want to miss any other Tech Talk video, don’t forget to subscribe to this channel. Also, if you want to check out my channel, Control System Lectures, I cover more control topics there as well. Thanks for watching, and I’ll see you next time.