Avoid Numerical Issues When Fitting Custom Distributions
This example shows how to use advanced techniques with the mle function to avoid numerical issues when fitting a custom distribution. Specifically, you learn how to:
Specify adequate initial parameter values.
Specify
logpdf(logarithm of probability density function) andlogsf(logarithm of survival function).Specify
nloglf(negative loglikelihood function) and supply the gradient vector of the negative loglikelihood to the optimization functionfmincon(requires Optimization Toolbox™).
In this example, you fit an extreme value distribution to right-censored data. An extreme value distribution is often used to model failure times of mechanical parts. These types of experiments typically run for a fixed length of time only. If not all of the experimental units fail within that time, then the data values are right-censored, meaning some failure time values are not known exactly, but are known to be larger than a certain value.
Both the evfit function and mle function fit an extreme value distribution to data, including data with censoring. However, for the purposes of this example, use mle and custom distributions to fit a model to censored data, using the extreme value distribution.
Specify Adequate Initial Parameter Values
Because the values for the censored data are not known exactly, maximum likelihood estimation requires more information. In particular, the probability density function (pdf), the cumulative distribution function (cdf), and adequate initial parameter values are necessary to compute the loglikelihood. You can use the evpdf and evcdf functions to specify the pdf and cdf.
First, generate some uncensored extreme value data.
rng(0,'twister');
n = 50;
mu = 5;
sigma = 2.5;
x = evrnd(mu,sigma,n,1);Next, censor any values that are larger than a predetermined cutoff by replacing those values with the cutoff value. This type of censoring is known as Type II censoring.
c = (x > 7); x(c) = 7;
Check the percentage of censored observations.
sum(c)/length(c)
ans = 0.1200
Twelve percent of the original data is right-censored with the cutoff at 7.
Plot a histogram of the data, including a stacked bar to represent the censored observations.
[uncensCnts,Edges] = histcounts(x(~c),10); censCnts = histcounts(x(c),Edges); bar(Edges(1:end-1)+diff(Edges)/2,[uncensCnts' censCnts'],'stacked') legend('Fully observed data','Censored data','Location','northwest')
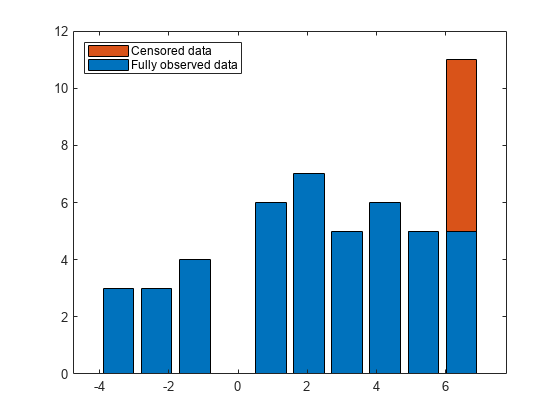
Although the data includes censored observations, the fraction of censored observations is relatively small. Therefore, the method of moments can provide reasonable starting points for the parameter estimates. Compute the initial parameter values of mu and sigma that correspond to the observed mean and standard deviation of the uncensored data.
sigma0 = sqrt(6)*std(x(~c))./pi
sigma0 = 2.3495
mu0 = mean(x(~c))-psi(1).*sigma0
mu0 = 3.5629
Find the maximum likelihood estimates of the two extreme value distribution parameters, as well as the approximate 95% confidence intervals. Specify the censoring vector, pdf, cdf, and initial parameter values. Because sigma (scale parameter) must be positive, you also need to specify lower parameter bounds.
[paramEsts,paramCIs] = mle(x,'Censoring',c, ... 'pdf',@evpdf,'cdf',@evcdf, ... 'Start',[mu0 sigma0],'LowerBound',[-Inf,0])
paramEsts = 1×2
4.5530 3.0215
paramCIs = 2×2
3.6455 2.2937
5.4605 3.7494
Specify logpdf and logsf
Fitting a custom distribution requires an initial guess for the parameters, and determining how good or bad a starting point is a priori can be difficult. If you specify a starting point that is farther away from the maximum likelihood estimates, some observations can be located far out in the tails of the extreme value distribution corresponding to the starting point. In a such case, one of these conditions can occur:
One of the pdf values becomes so small that it underflows to zero in double precision arithmetic.
One of the cdf values becomes so close to 1 that it rounds up in double precision.
A cdf value might also become so small as that it underflows, but this condition does not pose a problem.
Either condition can cause problems when mle computes the loglikelihood, because each leads to loglikelihood values of —Inf, which the optimization algorithm in mle cannot handle.
Examine what happens with a different starting point.
start = [1 1]; try [paramEsts,paramCIs] = mle(x,'Censoring',c, ... 'pdf',@evpdf,'cdf',@evcdf, ... 'Start',start,'LowerBound',[-Inf,0]) catch ME disp(ME.message) end
Custom cumulative distribution function returned values greater than or equal to 1.
In this case, the second problem condition occurs. Some of the cdf values at the initial parameter guess are exactly 1, so the loglikelihood is infinite. You can try setting the FunValCheck control parameter to off by using the Options name-value argument. The off option disables checking for nonfinite likelihood values. However, the best way to solve this numerical problem is at its root.
The extreme value cdf has the form
p = 1 - exp(-exp((x-mu)./sigma))
The contribution of the censored observations to the loglikelihood is the log of their survival function (SF) values, or log(1-cdf). For the extreme value distribution, the log of the SF is -exp((x-mu)./sigma). If you compute the loglikelihood using the log SF directly, instead of computing log(1-(1-exp(logSF))), you can avoid the rounding issues with the cdf. Observations whose cdf values are not distinguishable from 1 in double precision have log SF values that are easily representable as nonzero values. For example, a cdf value of (1-1e-20) rounds to 1 in double precision, because double precision eps is about 2e-16.
SFval = 1e-20; cdfval = 1 - SFval
cdfval = 1
The software can easily represent the log of the corresponding SF value.
log(SFval)
ans = -46.0517
The same situation is true for the log pdf; the contribution of uncensored observations to the loglikelihood is the log of their pdf values. You can use the log pdf directly, instead of computing log(exp(logpdf)), to avoid underflow problems where the pdf is not distinguishable from zero in double precision. The software can easily represent the log pdf as a finite negative number. For example, a pdf value of 1e-400 underflows in double precision, because double precision realmin is about 2e-308.
logpdfval = -921; pdfval = exp(logpdfval)
pdfval = 0
Using the mle function, you can specify a custom distribution with the log pdf and the log SF (rather than the pdf and cdf) by setting the logpdf and logsf name-value arguments. Unlike the pdf and cdf functions, log pdf and log SF do not have built-in functions. Therefore, you need to create anonymous functions that compute these values.
evlogpdf = @(x,mu,sigma) ((x-mu)./sigma - exp((x-mu)./sigma)) - log(sigma); evlogsf = @(x,mu,sigma) -exp((x-mu)./sigma);
Using the same starting point, the alternate log pdf and log SF specification of the extreme value distribution makes the problem solvable.
start = [1 1]; [paramEsts,paramCIs] = mle(x,'Censoring',c, ... 'logpdf',evlogpdf,'logsf',evlogsf, ... 'Start',start,'LowerBound',[-Inf,0])
paramEsts = 1×2
4.5530 3.0215
paramCIs = 2×2
3.6455 2.2937
5.4605 3.7494
This process does not always fix the problem of a poor starting point, so choosing the starting point carefully is recommended.
Supply Gradient to Optimization Function fmincon
By default, mle uses the function fminsearch to find parameter values that maximize the loglikelihood for a custom distribution. fminsearch uses an optimization algorithm that is derivative free, making it a good choice for this type of problem. However, for some problems, choosing an optimization algorithm that uses the derivatives of the loglikelihood function can make the difference between converging to the maximum likelihood estimates or not, especially when the starting point is far away from the final answer. Providing the derivatives can also speed up the convergence.
You can specify the OptimFun name-value argument in mle as fmincon to use the fmincon function (requires Optimization Toolbox). The fmincon function includes optimization algorithms that can use derivative information. To take advantage of the algorithms in fmincon, specify a custom distribution using a loglikelihood function, written to return not only the loglikelihood, but its gradient as well. The gradient of the loglikelihood function is the vector of its partial derivatives with respect to its parameters.
This strategy requires extra preparation to write code that computes both the loglikelihood and its gradient. Define a function named helper_evnegloglike in a separate file.
function [nll,ngrad] = helper_evnegloglike(params,x,cens,freq) %HELPER_EVNEGLOGLIKE Negative log-likelihood for the extreme value % distribution. % This function supports only the example Avoid Numerical Issues When % Fitting Custom Distributions (customdist2demo.mlx) and might change in % a future release. if numel(params)~=2 error(message('stats:probdists:WrongParameterLength',2)); end mu = params(1); sigma = params(2); nunc = sum(1-cens); z = (x - mu) ./ sigma; expz = exp(z); nll = sum(expz) - sum(z(~cens)) + nunc.*log(sigma); if nargout > 1 ngrad = [-sum(expz)./sigma + nunc./sigma, ... -sum(z.*expz)./sigma + sum(z(~cens))./sigma + nunc./sigma]; end
The function helper_evnegloglike returns the negative of both the loglikelihood values and the gradient values because mle minimizes the negative loglikelihood.
To compute the maximum likelihood estimates using a gradient-based optimization algorithm, specify the nloglf, OptimFun, and Options name-value arguments. nloglf specifies the custom function that computes the negative loglikelihood, OptimFun specifies fmincon as the optimization function, and Options specifies that fmincon uses the second output of the custom function for the gradient.
start = [1 1]; [paramEsts,paramCIs] = mle(x,'Censoring',c,'nloglf',@helper_evnegloglike, ... 'Start',start,'LowerBound',[-Inf,0], ... 'OptimFun','fmincon','Options',statset('GradObj','on'))
paramEsts = 1×2
4.5530 3.0215
paramCIs = 2×2
3.6455 2.2937
5.4605 3.7493
See Also
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)