pivot
Syntax
Description
A pivoted table provides a summary of tabular data—the column and row labels of a pivoted table are group names, and the data values are group counts or the result of another computation method. Pivoted tables are useful for analyzing and providing insights into large data sets and organizing data from another perspective, according to column and row groups. For more information, see Pivoting Operation.
P = pivot(
returns a pivoted table that summarizes data in the table or timetable T,Columns=colvars,Rows=rowvars)T.
The groups in the grouping variables specified by colvars designate the
variables in the pivoted table. The group names in the grouping variables specified by
rowvars designate the values of the row labels of the pivoted table.
The default data in P is the group counts of each combination of groups
from colvars and rowvars. Empty categories are omitted
from the pivoted table, where an empty category is a possible value of a categorical,
logical, or binned numeric, duration, or datetime grouping variable that is not represented
in the input table.
P = pivot(___,
specifies additional pivoting parameters using one or more name-value arguments with any of
the input argument combinations in the previous syntaxes. For example,
Name=Value)pivot(T,Columns=colvars,DataVariable="Sales") returns a pivoted table
where the data values are the sums of the numeric data variable
Sales.
Examples
Summarize Table Using Cross-Tabulation
Compute the group counts for table data with two grouping variables.
Create a table that contains information about 12 hospital patients.
healthStatusOrder = ["Poor" "Fair" "Good" "Excellent"]; HealthStatus = categorical(["Excellent"; "Fair"; "Good"; "Fair"; "Good"; "Good"; ... "Good"; "Good"; "Excellent"; "Excellent"; "Excellent"; "Poor"],healthStatusOrder); Smoker = logical([1; 0; 0; 0; 0; 0; 1; 0; 0; 0; 0; 0]); Location = ["County"; "VA"; "St. Mary's"; "VA"; "County"; "St. Mary's"; ... "VA"; "VA"; "St. Mary's"; "County"; "County"; "St. Mary's"]; T = table(HealthStatus,Smoker,Location)
T=12×3 table
HealthStatus Smoker Location
____________ ______ ____________
Excellent true "County"
Fair false "VA"
Good false "St. Mary's"
Fair false "VA"
Good false "County"
Good false "St. Mary's"
Good true "VA"
Good false "VA"
Excellent false "St. Mary's"
Excellent false "County"
Excellent false "County"
Poor false "St. Mary's"
Find the number of patients reporting each unique combination of smoker status and health status. The variables in the pivoted table represent the unique values of the Smoker grouping variable. The rows in the pivoted table represent the unique values of the HealthStatus grouping variable.
For example, the true variable in the pivoted table shows that one smoking patient reported Good health status and one smoking patient reported Excellent health status.
P = pivot(T,Columns="Smoker",Rows="HealthStatus")
P=4×3 table
HealthStatus false true
____________ _____ ____
Poor 1 0
Fair 2 0
Good 4 1
Excellent 3 1
Specify Computation Method
Compute a summary statistic for filtered and grouped table data.
Create a table from a file that contains information about 100 hospital patients.
T = readtable("patients.xls",TextType="string"); healthStatusOrder = ["Poor" "Fair" "Good" "Excellent"]; T.SelfAssessedHealthStatus = categorical(T.SelfAssessedHealthStatus,healthStatusOrder);
Create a table containing data for patients at the County General Hospital.
T_cgh = T(T.Location=="County General Hospital",:)T_cgh=39×10 table
LastName Gender Age Location Height Weight Smoker Systolic Diastolic SelfAssessedHealthStatus
___________ ________ ___ _________________________ ______ ______ ______ ________ _________ ________________________
"Smith" "Male" 38 "County General Hospital" 71 176 true 124 93 Excellent
"Brown" "Female" 49 "County General Hospital" 64 119 false 122 80 Good
"Taylor" "Female" 31 "County General Hospital" 66 132 false 118 86 Excellent
"Anderson" "Female" 45 "County General Hospital" 68 128 false 114 77 Excellent
"Martinez" "Male" 37 "County General Hospital" 70 179 false 119 77 Good
"Robinson" "Male" 50 "County General Hospital" 68 172 false 125 76 Good
"Lee" "Female" 44 "County General Hospital" 66 146 true 128 90 Fair
"Walker" "Female" 28 "County General Hospital" 65 123 true 129 96 Good
"Young" "Female" 25 "County General Hospital" 63 114 false 125 76 Good
"Hernandez" "Male" 36 "County General Hospital" 68 166 false 120 83 Poor
"King" "Male" 30 "County General Hospital" 67 186 true 127 89 Excellent
"Green" "Male" 44 "County General Hospital" 71 193 false 121 92 Good
"Mitchell" "Male" 39 "County General Hospital" 71 164 true 128 92 Fair
"Campbell" "Female" 37 "County General Hospital" 65 135 false 116 77 Fair
"Evans" "Female" 39 "County General Hospital" 62 121 false 123 76 Good
"Edwards" "Male" 42 "County General Hospital" 70 158 false 116 83 Excellent
⋮
Find the median age of nonsmoking and smoking patients per health status at the County General Hospital.
P = pivot(T_cgh,Columns="Smoker",Rows="SelfAssessedHealthStatus",Method="median",DataVariable="Age")
P=4×3 table
SelfAssessedHealthStatus false true
________________________ _____ ____
Poor 36 43
Fair 42.5 41.5
Good 39 39
Excellent 42 38
Specify Group Bins
Compute the group counts for table data with two discretized grouping variables.
Create a timetable from a file that contains information about 1468 power outages.
TT = readtimetable("outages.csv",TextType="string")
TT=1468×5 timetable
OutageTime Region Loss Customers RestorationTime Cause
____________________ ___________ ______ __________ ____________________ _________________
01-Feb-2002 12:18:00 "SouthWest" 458.98 1.8202e+06 07-Feb-2002 16:50:00 "winter storm"
23-Jan-2003 00:49:00 "SouthEast" 530.14 2.1204e+05 NaT "winter storm"
07-Feb-2003 21:15:00 "SouthEast" 289.4 1.4294e+05 17-Feb-2003 08:14:00 "winter storm"
06-Apr-2004 05:44:00 "West" 434.81 3.4037e+05 06-Apr-2004 06:10:00 "equipment fault"
16-Mar-2002 06:18:00 "MidWest" 186.44 2.1275e+05 18-Mar-2002 23:23:00 "severe storm"
18-Jun-2003 02:49:00 "West" 0 0 18-Jun-2003 10:54:00 "attack"
20-Jun-2004 14:39:00 "West" 231.29 NaN 20-Jun-2004 19:16:00 "equipment fault"
06-Jun-2002 19:28:00 "West" 311.86 NaN 07-Jun-2002 00:51:00 "equipment fault"
16-Jul-2003 16:23:00 "NorthEast" 239.93 49434 17-Jul-2003 01:12:00 "fire"
27-Sep-2004 11:09:00 "MidWest" 286.72 66104 27-Sep-2004 16:37:00 "equipment fault"
05-Sep-2004 17:48:00 "SouthEast" 73.387 36073 05-Sep-2004 20:46:00 "equipment fault"
21-May-2004 21:45:00 "West" 159.99 NaN 22-May-2004 04:23:00 "equipment fault"
01-Sep-2002 18:22:00 "SouthEast" 95.917 36759 01-Sep-2002 19:12:00 "severe storm"
27-Sep-2003 07:32:00 "SouthEast" NaN 3.5517e+05 04-Oct-2003 07:02:00 "severe storm"
12-Nov-2003 06:12:00 "West" 254.09 9.2429e+05 17-Nov-2003 02:04:00 "winter storm"
18-Sep-2004 05:54:00 "NorthEast" 0 0 NaT "equipment fault"
⋮
Compute the total number of customers impacted by power outages for each region per year. The default computation method for the numeric variable Customers is "sum".
P = pivot(TT,Columns="Region",Rows="OutageTime",RowsBinMethod="year",DataVariable="Customers")
P=13×6 table
year_OutageTime MidWest NorthEast SouthEast SouthWest West
_______________ __________ __________ __________ __________ __________
2002 5.0288e+06 3.3639e+06 1.2407e+06 2.7917e+06 6.2711e+05
2003 1.6592e+06 2.2939e+06 6.14e+06 1.3498e+06 2.5174e+06
2004 1.6618e+06 8.8251e+05 9.7505e+06 7.288e+05 2.4995e+06
2005 4.0282e+05 2.1882e+06 4.4938e+06 63303 1.5852e+06
2006 5.893e+06 4.5673e+06 6.1276e+06 2.8699e+05 8.8541e+06
2007 1.2878e+06 5.713e+06 2.6545e+06 64318 2.774e+06
2008 5.8309e+06 7.6436e+06 2.4609e+06 5.18e+05 1.1541e+06
2009 1.7014e+06 5.4466e+06 3.0844e+06 1.3161e+05 1.421e+06
2010 1.276e+06 1.5478e+07 6.3296e+06 0 4.5303e+06
2011 2.6649e+06 6.4766e+06 2.5454e+06 0 1.9269e+06
2012 1.3579e+06 1.1328e+07 4.8136e+06 0 1.4055e+06
2013 5.3376e+05 5.7699e+06 3.8738e+06 0 1.1063e+06
2014 0 0 0 0 0
More Than Two Grouping Variables
Compute the group counts for table data with more than two grouping variables.
Create a table from a file that contains information about 100 hospital patients.
T = readtable("patients.xls",TextType="string"); healthStatusOrder = ["Poor" "Fair" "Good" "Excellent"]; T.SelfAssessedHealthStatus = categorical(T.SelfAssessedHealthStatus,healthStatusOrder); T
T=100×10 table
LastName Gender Age Location Height Weight Smoker Systolic Diastolic SelfAssessedHealthStatus
__________ ________ ___ ___________________________ ______ ______ ______ ________ _________ ________________________
"Smith" "Male" 38 "County General Hospital" 71 176 true 124 93 Excellent
"Johnson" "Male" 43 "VA Hospital" 69 163 false 109 77 Fair
"Williams" "Female" 38 "St. Mary's Medical Center" 64 131 false 125 83 Good
"Jones" "Female" 40 "VA Hospital" 67 133 false 117 75 Fair
"Brown" "Female" 49 "County General Hospital" 64 119 false 122 80 Good
"Davis" "Female" 46 "St. Mary's Medical Center" 68 142 false 121 70 Good
"Miller" "Female" 33 "VA Hospital" 64 142 true 130 88 Good
"Wilson" "Male" 40 "VA Hospital" 68 180 false 115 82 Good
"Moore" "Male" 28 "St. Mary's Medical Center" 68 183 false 115 78 Excellent
"Taylor" "Female" 31 "County General Hospital" 66 132 false 118 86 Excellent
"Anderson" "Female" 45 "County General Hospital" 68 128 false 114 77 Excellent
"Thomas" "Female" 42 "St. Mary's Medical Center" 66 137 false 115 68 Poor
"Jackson" "Male" 25 "VA Hospital" 71 174 false 127 74 Poor
"White" "Male" 39 "VA Hospital" 72 202 true 130 95 Excellent
"Harris" "Female" 36 "St. Mary's Medical Center" 65 129 false 114 79 Good
"Martin" "Male" 48 "VA Hospital" 71 181 true 130 92 Good
⋮
Find the number of nonsmoking and smoking patients declaring each health status per location. The pivoted table is 3-by-5 and contains nested variables that retain the hierarchy of the SelfAssessedHealthStatus and Smoker variables.
P = pivot(T,Columns=["SelfAssessedHealthStatus" "Smoker"],Rows="Location")
P=3×5 table
Location Poor Fair Good Excellent
false true false true false true false true
___________________________ _____________ _____________ _____________ _____________
"County General Hospital" 1 3 4 2 9 7 9 4
"St. Mary's Medical Center" 3 0 2 0 10 3 4 2
"VA Hospital" 4 0 4 3 5 6 11 4
Access a data value by indexing into the pivoted table. For example, return the number of smoking patients reporting Fair health from the County General Hospital.
num = P.Fair.true(P.Location == "County General Hospital")num = 2
Alternatively, return a table containing only one level. Flatten the hierarchy of the SelfAssessedHealthStatus and Smoker grouping variables and concatenate their group names with an underscore.
Pflat = pivot(T,Columns=["SelfAssessedHealthStatus" "Smoker"],Rows="Location",OutputFormat="flat")
Pflat=3×9 table
Location Poor_false Poor_true Fair_false Fair_true Good_false Good_true Excellent_false Excellent_true
___________________________ __________ _________ __________ _________ __________ _________ _______________ ______________
"County General Hospital" 1 3 4 2 9 7 9 4
"St. Mary's Medical Center" 3 0 2 0 10 3 4 2
"VA Hospital" 4 0 4 3 5 6 11 4
Include Totals
Compute the overall counts for each variable and row in a pivoted table.
Create a table T that contains information about 12 hospital patients.
healthStatusOrder = ["Poor" "Fair" "Good" "Excellent"]; HealthStatus = categorical(["Excellent"; "Fair"; "Good"; "Fair"; "Good"; "Good"; ... "Good"; "Good"; "Excellent"; "Excellent"; "Excellent"; "Poor"],healthStatusOrder); Smoker = logical([1; 0; 0; 0; 0; 0; 1; 0; 0; 0; 0; 0]); Location = ["County"; "VA"; "St. Mary's"; "VA"; "County"; "St. Mary's"; ... "VA"; "VA"; "St. Mary's"; "County"; "County"; "St. Mary's"]; T = table(HealthStatus,Smoker,Location)
T=12×3 table
HealthStatus Smoker Location
____________ ______ ____________
Excellent true "County"
Fair false "VA"
Good false "St. Mary's"
Fair false "VA"
Good false "County"
Good false "St. Mary's"
Good true "VA"
Good false "VA"
Excellent false "St. Mary's"
Excellent false "County"
Excellent false "County"
Poor false "St. Mary's"
Find the number of patients reporting each unique combination of smoker status and health status. To display the total number of patients reporting each smoker status and health status, include the variable and row totals in the pivoted table. Move the row labels in the HealthStatus variable into the RowNames property and display the pivoted table.
P = pivot(T,Columns="Smoker",Rows="HealthStatus",IncludeTotals=true,RowLabelPlacement="rownames")
P=5×3 table
false true Overall_count
_____ ____ _____________
Poor 1 0 1
Fair 2 0 2
Good 4 1 5
Excellent 3 1 4
Overall_count 10 2 12
Return a subset of the pivoted table containing the specified row names.
Psubset = P(["Good" "Excellent"],:)
Psubset=2×3 table
false true Overall_count
_____ ____ _____________
Good 4 1 5
Excellent 3 1 4
Include Empty Groups
Compute the group counts for filtered and grouped timetable data. Include unrepresented groups in the pivoting operation.
Create a timetable from a file that contains information about 1468 power outages.
TT = readtimetable("outages.csv")TT=1468×5 timetable
OutageTime Region Loss Customers RestorationTime Cause
____________________ _____________ ______ __________ ____________________ ___________________
01-Feb-2002 12:18:00 {'SouthWest'} 458.98 1.8202e+06 07-Feb-2002 16:50:00 {'winter storm' }
23-Jan-2003 00:49:00 {'SouthEast'} 530.14 2.1204e+05 NaT {'winter storm' }
07-Feb-2003 21:15:00 {'SouthEast'} 289.4 1.4294e+05 17-Feb-2003 08:14:00 {'winter storm' }
06-Apr-2004 05:44:00 {'West' } 434.81 3.4037e+05 06-Apr-2004 06:10:00 {'equipment fault'}
16-Mar-2002 06:18:00 {'MidWest' } 186.44 2.1275e+05 18-Mar-2002 23:23:00 {'severe storm' }
18-Jun-2003 02:49:00 {'West' } 0 0 18-Jun-2003 10:54:00 {'attack' }
20-Jun-2004 14:39:00 {'West' } 231.29 NaN 20-Jun-2004 19:16:00 {'equipment fault'}
06-Jun-2002 19:28:00 {'West' } 311.86 NaN 07-Jun-2002 00:51:00 {'equipment fault'}
16-Jul-2003 16:23:00 {'NorthEast'} 239.93 49434 17-Jul-2003 01:12:00 {'fire' }
27-Sep-2004 11:09:00 {'MidWest' } 286.72 66104 27-Sep-2004 16:37:00 {'equipment fault'}
05-Sep-2004 17:48:00 {'SouthEast'} 73.387 36073 05-Sep-2004 20:46:00 {'equipment fault'}
21-May-2004 21:45:00 {'West' } 159.99 NaN 22-May-2004 04:23:00 {'equipment fault'}
01-Sep-2002 18:22:00 {'SouthEast'} 95.917 36759 01-Sep-2002 19:12:00 {'severe storm' }
27-Sep-2003 07:32:00 {'SouthEast'} NaN 3.5517e+05 04-Oct-2003 07:02:00 {'severe storm' }
12-Nov-2003 06:12:00 {'West' } 254.09 9.2429e+05 17-Nov-2003 02:04:00 {'winter storm' }
18-Sep-2004 05:54:00 {'NorthEast'} 0 0 NaT {'equipment fault'}
⋮
Filter the timetable for outages where the cause was a winter storm.
TT.Cause = categorical(TT.Cause);
TTwinter = TT(TT.Cause=="winter storm",:);Add a variable to the timetable that contains the duration of each power outage in days.
TTwinter.OutageDuration = TTwinter.RestorationTime-TTwinter.OutageTime;
TTwinter.OutageDuration.Format = "d"TTwinter=145×6 timetable
OutageTime Region Loss Customers RestorationTime Cause OutageDuration
____________________ _____________ ______ __________ ____________________ ____________ ______________
01-Feb-2002 12:18:00 {'SouthWest'} 458.98 1.8202e+06 07-Feb-2002 16:50:00 winter storm 6.1889 days
23-Jan-2003 00:49:00 {'SouthEast'} 530.14 2.1204e+05 NaT winter storm NaN days
07-Feb-2003 21:15:00 {'SouthEast'} 289.4 1.4294e+05 17-Feb-2003 08:14:00 winter storm 9.4576 days
12-Nov-2003 06:12:00 {'West' } 254.09 9.2429e+05 17-Nov-2003 02:04:00 winter storm 4.8278 days
13-Nov-2004 10:42:00 {'NorthEast'} NaN 1.4227e+05 19-Nov-2004 02:31:00 winter storm 5.659 days
06-Dec-2004 23:18:00 {'SouthEast'} NaN 37136 14-Dec-2004 03:21:00 winter storm 7.1688 days
12-Dec-2002 18:08:00 {'SouthEast'} 46.918 1.0698e+05 14-Dec-2002 18:43:00 winter storm 2.0243 days
21-Dec-2004 18:50:00 {'West' } 112.05 7.985e+05 29-Dec-2004 03:46:00 winter storm 7.3722 days
16-Dec-2002 13:43:00 {'West' } 70.752 4.8193e+05 19-Dec-2002 09:38:00 winter storm 2.8299 days
26-Dec-2004 22:18:00 {'NorthEast'} 255.45 1.0444e+05 27-Dec-2004 14:11:00 winter storm 0.66181 days
17-Dec-2003 15:11:00 {'NorthEast'} NaN 66692 19-Dec-2003 07:22:00 winter storm 1.6743 days
08-Mar-2005 16:37:00 {'SouthEast'} 1339.2 4.3003e+05 10-Mar-2005 20:42:00 winter storm 2.1701 days
26-Mar-2002 01:59:00 {'MidWest' } 388.04 5.6422e+05 28-Mar-2002 19:55:00 winter storm 2.7472 days
22-Dec-2003 03:40:00 {'West' } 232.26 3.9462e+05 24-Dec-2003 16:32:00 winter storm 2.5361 days
10-Jan-2003 15:38:00 {'West' } 185.85 2.757e+05 12-Jan-2003 05:48:00 winter storm 1.5903 days
30-Dec-2002 07:53:00 {'West' } 119.78 1.0355e+05 02-Jan-2003 11:17:00 winter storm 3.1417 days
⋮
Compute the number of winter storm outages that occurred during each month of the year per the duration of the outage in days.
Pwinter = pivot(TTwinter,Rows="RestorationTime",Columns="OutageDuration",RowsBinMethod="monthname",ColumnsBinMethod="day",RowLabelPlacement="rownames")
Pwinter=9×16 table
[0 days, 1 day) [1 day, 2 days) [2 days, 3 days) [3 days, 4 days) [4 days, 5 days) [5 days, 6 days) [6 days, 7 days) [7 days, 8 days) [8 days, 9 days) [9 days, 10 days) [10 days, 11 days) [11 days, 12 days) [12 days, 13 days) [14 days, 15 days) [18 days, 19 days] <missing_day_OutageDuration>
_______________ _______________ ________________ ________________ ________________ ________________ ________________ ________________ ________________ _________________ __________________ __________________ __________________ __________________ __________________ ____________________________
January 5 10 5 2 4 1 1 0 1 1 2 0 2 0 0 0
February 13 12 8 5 2 3 3 2 2 1 0 1 0 1 1 0
March 3 1 6 2 0 0 0 0 0 0 0 0 0 0 0 0
April 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0
May 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0
October 1 1 1 0 0 1 0 0 0 0 1 0 0 0 0 0
November 3 2 0 2 2 1 0 0 0 0 0 0 0 0 0 0
December 4 1 7 3 0 1 2 2 1 0 2 0 0 1 0 0
<missing_monthname_RestorationTime> 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 2
Include groups in the pivoting operation for categories in RestorationTime and OutageDuration that are unrepresented in the input table. Including empty groups creates rows for June, July, August, and September in the pivoted table, where the value of every table cell in those rows is 0. Including empty groups also creates variables for outage durations that are not present in the data set, where the value of every table cell in those variables is 0. Do not include groups in the pivoted table for outages with an unknown restoration time.
Pwinter2 = pivot(TTwinter,Rows="RestorationTime",Columns="OutageDuration",RowsBinMethod="monthname",ColumnsBinMethod="day",IncludeEmptyGroups=1,IncludeMissingGroups=0,RowLabelPlacement="rownames")
Pwinter2=12×19 table
[0 days, 1 day) [1 day, 2 days) [2 days, 3 days) [3 days, 4 days) [4 days, 5 days) [5 days, 6 days) [6 days, 7 days) [7 days, 8 days) [8 days, 9 days) [9 days, 10 days) [10 days, 11 days) [11 days, 12 days) [12 days, 13 days) [13 days, 14 days) [14 days, 15 days) [15 days, 16 days) [16 days, 17 days) [17 days, 18 days) [18 days, 19 days]
_______________ _______________ ________________ ________________ ________________ ________________ ________________ ________________ ________________ _________________ __________________ __________________ __________________ __________________ __________________ __________________ __________________ __________________ __________________
January 5 10 5 2 4 1 1 0 1 1 2 0 2 0 0 0 0 0 0
February 13 12 8 5 2 3 3 2 2 1 0 1 0 0 1 0 0 0 1
March 3 1 6 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
April 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
May 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
June 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
July 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
August 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
September 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
October 1 1 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0
November 3 2 0 2 2 1 0 0 0 0 0 0 0 0 0 0 0 0 0
December 4 1 7 3 0 1 2 2 1 0 2 0 0 0 1 0 0 0 0
Input Arguments
T — Input table
table | timetable
Input table, specified as a table or timetable.
colvars — Grouping variables to designate pivoted table variables
scalar | vector | cell array | pattern | function handle | table vartype subscript
Grouping variables to designate pivoted table variables, specified as one of the
indexing schemes in this table. This argument specifies the variables for
Columns. Each variable in the pivoted table corresponds to one
variable group. Variable groups are defined by rows that have the same unique
combination of values in grouping variables in Columns.
If you do not specify colvars, then the pivoted table contains
only one variable.
| Indexing Scheme | Examples |
|---|---|
Variable names:
|
|
Variable index:
|
|
Function handle:
|
|
Variable type:
|
|
Example: P = pivot(T,Columns="Var1",Rows="Var2")
Example: P = pivot(T,Columns=["Var1"
"Var2"],Rows="Var3")
rowvars — Grouping variables to designate pivoted table rows
scalar | vector | cell array | pattern | function handle | table vartype subscript
Grouping variables to designate pivoted table rows, specified as one of the indexing
schemes in this table. This argument specifies the variables for
Rows. Each row in the pivoted table corresponds to one row group. Row
groups are defined by rows that have the same unique combination of values in grouping
variables in Rows.
If you do not specify rowvars, then the pivoted table contains
only one row.
| Indexing Scheme | Examples |
|---|---|
Variable names:
|
|
Variable index:
|
|
Function handle:
|
|
Variable type:
|
|
Example: P = pivot(T,Columns="Var1",Rows="Var2")
Example: P = pivot(T,Columns="Var1",Rows=["Var2"
"Var3"])
Name-Value Arguments
Specify optional pairs of arguments as
Name1=Value1,...,NameN=ValueN, where Name is
the argument name and Value is the corresponding value.
Name-value arguments must appear after other arguments, but the order of the
pairs does not matter.
Example: P = pivot(T,Columns=["Var1"
"Var2"],Rows="Var3","DataVariable="Var4",Method="mean")
DataVariable — Table variable to fill values of the pivoted table
scalar | vector | function handle | table vartype subscript
Table variable to fill values of the pivoted table instead of group counts, specified as one
of the indexing schemes in this table. The results of applying the computation method
Method to the variable specified by DataVariable are the
data values of the pivoted table.
If you do not specify DataVariable, then the data values of the pivoted
table are the group counts.
| Indexing Scheme | Examples |
|---|---|
Variable name:
|
|
Variable index:
|
|
Function handle:
|
|
Variable type:
|
|
To apply a computation method to multiple data variables, use the groupsummary
function.
Example: P =
pivot(T,Columns="Var1",Rows="Var2",DataVariable="Var3")
Method — Computation method to apply to the data variable
"count" | "sum" | "mean" | "median" | "std" | function handle | ...
Computation method to apply to the data variable, specified as one of the values in this
table. The results of applying the computation method to the variable specified by
DataVariable are the data values of the pivoted table.
The default value of Method depends on the value of
DataVariable.
If the variable specified by
DataVariableis numeric, then the default computation method is"sum".If the variable specified by
DataVariableis not numeric, then the default computation method is"count".If
DataVariableis not specified, then the computation method must be"count"or"percentage", where"count"is the default.
Method | Description |
|---|---|
"count" | Group count |
"sum" | Sum |
"percentage" | Group percentage |
"mean" | Mean |
"median" | Median |
"mode" | Mode |
"var" | Variance |
"std" | Standard deviation |
"min" | Minimum |
"max" | Maximum |
"range" | Maximum minus minimum |
"nummissing" | Number of missing elements |
"numunique" | Number of distinct nonmissing elements |
"nnz" | Number of nonzero and non- |
You also can specify the computation method as a function handle that accepts groups of data
in DataVariable and returns one output per group whose first dimension has
length 1.
The pivot function omits missing values in the input data
when using the method names described here, with the exception of
"nummissing". To include missing values, use a function handle
for the method, such as @sum instead of
"sum".
To specify multiple computation methods for a data variable, use the groupsummary
function.
Example: P =
pivot(T,Columns="Var1",Rows="Var2",DataVariable="Var3",Method="mean")
ColumnsBinMethod — Binning scheme for grouping variables specified by Columns
"none" (default) | vector of bin edges | number of bins | length of time (bin width) | name of time unit (bin width) | cell array of binning methods
Binning scheme for grouping variables specified by Columns,
specified as one or more of the following binning methods. To apply the same binning
method to all grouping variables, specify one binning method. To apply a different
binning method to each grouping variable, specify a cell array of binning methods,
where each cell contains the binning method for the corresponding grouping
variable.
"none"— No binning.Vector of bin edges — The bin edges define the bins. You can specify the edges as numeric values or as
datetimevalues fordatetimegrouping variables.Number of bins — The number determines how many equally spaced bins to create. You can specify the number of bins as a positive integer scalar.
Length of time (bin width) — The length of time determines the width of each bin. You can specify the bin width as a
durationorcalendarDurationscalar fordatetimeordurationgrouping variables.Name of time unit (bin width) — The name of the time unit determines the width of each bin. You can specify the bin width as one of the options in this table for
datetimeordurationgrouping variables.Value Description Data Type "second"Each bin is 1 second.
datetimeandduration"minute"Each bin is 1 minute.
datetimeandduration"hour"Each bin is 1 hour.
datetimeandduration"day"Each bin is 1 calendar day. This value accounts for daylight saving time shifts.
datetimeandduration"week"Each bin is 1 calendar week. datetimeonly"month"Each bin is 1 calendar month. datetimeonly"quarter"Each bin is 1 calendar quarter. datetimeonly"year"Each bin is 1 calendar year. This value accounts for leap days.
datetimeandduration"decade"Each bin is 1 decade (10 calendar years). datetimeonly"century"Each bin is 1 century (100 calendar years). datetimeonly"secondofminute"Bins are seconds from 0 to 59.
datetimeonly"minuteofhour"Bins are minutes from 0 to 59.
datetimeonly"hourofday"Bins are hours from 0 to 23.
datetimeonly"dayofweek"Bins are days from 1 to 7. The first day of the week is Sunday.
datetimeonly"dayname"Bins are full day names, such as "Sunday".datetimeonly"dayofmonth"Bins are days from 1 to 31. datetimeonly"dayofyear"Bins are days from 1 to 366. datetimeonly"weekofmonth"Bins are weeks from 1 to 6. datetimeonly"weekofyear"Bins are weeks from 1 to 54. datetimeonly"monthname"Bins are full month names, such as "January".datetimeonly"monthofyear"Bins are months from 1 to 12.
datetimeonly"quarterofyear"Bins are quarters from 1 to 4. datetimeonly
Example: P = pivot(T,Columns="Var1",Rows="Var2",ColumnsBinMethod=[-Inf 0
Inf])
Example: P = pivot(T,Columns=["Var1"
"Var2"],ColumnsBinMethod={"none","year"})
RowsBinMethod — Binning scheme for grouping variables specified by Rows
"none" (default) | vector of bin edges | number of bins | length of time (bin width) | name of time unit (bin width) | cell array of binning methods
Binning scheme for grouping variables specified by Rows,
specified as one or more of the following binning methods. To apply the same binning
method to all grouping variables, specify one binning method. To apply a different
binning method to each grouping variable, specify a cell array of binning methods,
where each cell contains the binning method for the corresponding grouping
variable.
"none"— No binning.Vector of bin edges — The bin edges define the bins. You can specify the edges as numeric values or as
datetimevalues fordatetimegrouping variables.Number of bins — The number determines how many equally spaced bins to create. You can specify the number of bins as a positive integer scalar.
Length of time (bin width) — The length of time determines the width of each bin. You can specify the bin width as a
durationorcalendarDurationscalar fordatetimeordurationgrouping variables.Name of time unit (bin width) — The name of the time unit determines the width of each bin. You can specify the bin width as one of the options in this table for
datetimeordurationgrouping variables.Value Description Data Type "second"Each bin is 1 second.
datetimeandduration"minute"Each bin is 1 minute.
datetimeandduration"hour"Each bin is 1 hour.
datetimeandduration"day"Each bin is 1 calendar day. This value accounts for daylight saving time shifts.
datetimeandduration"week"Each bin is 1 calendar week. datetimeonly"month"Each bin is 1 calendar month. datetimeonly"quarter"Each bin is 1 calendar quarter. datetimeonly"year"Each bin is 1 calendar year. This value accounts for leap days.
datetimeandduration"decade"Each bin is 1 decade (10 calendar years). datetimeonly"century"Each bin is 1 century (100 calendar years). datetimeonly"secondofminute"Bins are seconds from 0 to 59.
datetimeonly"minuteofhour"Bins are minutes from 0 to 59.
datetimeonly"hourofday"Bins are hours from 0 to 23.
datetimeonly"dayofweek"Bins are days from 1 to 7. The first day of the week is Sunday.
datetimeonly"dayname"Bins are full day names, such as "Sunday".datetimeonly"dayofmonth"Bins are days from 1 to 31. datetimeonly"dayofyear"Bins are days from 1 to 366. datetimeonly"weekofmonth"Bins are weeks from 1 to 6. datetimeonly"weekofyear"Bins are weeks from 1 to 54. datetimeonly"monthname"Bins are full month names, such as "January".datetimeonly"monthofyear"Bins are months from 1 to 12.
datetimeonly"quarterofyear"Bins are quarters from 1 to 4. datetimeonly
Example: P = pivot(T,Columns="Var1",Rows="Var2",RowsBinMethod=[-Inf 0
Inf])
Example: P = pivot(T,Rows=["Var1"
"Var2"],RowsBinMethod={"none","year"})
IncludedEdge — Included bin edge for binning scheme
"left" (default) | "right"
Included bin edge for binning scheme, specified as either "left" or
"right", indicating which end of the bin interval is inclusive when binning
the grouping variables.
You can specify IncludedEdge only if you also specify
ColumnsBinMethod or RowsBinMethod. The value
applies to all binning methods for all grouping variables.
Example: P = pivot(T,Columns="Var1",ColumnsBinMethod=[0 5 10
15],IncludedEdge="right",Rows="Var2")
OutputFormat — Column hierarchy output format
"nested" (default) | "flat"
Column hierarchy output format, specified as one of these values when more than
one grouping variable is specified by Columns:
"nested"— Variables in the pivoted table contain nested tables. The pivoted table retains the hierarchy of groups in the grouping variables specified byColumns."flat"— Variables in the pivoted table contain one level. The pivoted table flattens the hierarchy of groups in the variables specified byColumns, and the variable names are the group names concatenated with an underscore.
Example: P = pivot(T,Columns=["Var1"
"Var2"],Rows="Var3",OutputFormat="flat")
IncludeTotals — Option to include column and row totals
false or 0 (default) | true or 1
Option to include column and row totals, specified as a numeric or logical
0 (false) or 1
(true). If IncludeTotals is
true, then the pivoted table includes an additional row
containing the totals for each column and an additional variable containing the totals
for each row. The pivot function computes the marginal totals by
applying Method to all data values in
DataVariable that correspond to that column or row.
If you do not specify Columns, then the pivoted table contains
only one variable and omits the additional variable of row totals. If you do not
specify Rows, then the pivoted table contains only one row and
omits the additional row of column totals.
Example: P =
pivot(T,Columns="Var1",IncludeTotals=true)
Example: P =
pivot(T,Rows="Var2",IncludeTotals=true)
Example: P =
pivot(T,Columns="Var1",Rows="Var2",IncludeTotals=true)
IncludeMissingGroups — Option to treat missing values as a group
true or 1 (default) | false or 0
Option to treat missing values as a group, specified as a numeric or logical
1 (true) or 0
(false). If IncludeMissingGroups is
true, then pivot treats missing values, such as
NaN, in a grouping variable specified by Columns or
Rows as a group. If a grouping variable has no missing values, or if
IncludeMissingGroups is false, then
pivot does not treat missing values as a group.
Example: P =
pivot(T,Columns="Var1",Rows="Var2",IncludeMissingGroups=false)
IncludeEmptyGroups — Option to include empty categories in pivoting operation
false or 0 (default) | true or 1
Option to include empty categories in the pivoting operation, specified as a numeric or
logical 0 (false) or 1
(true). If IncludeEmptyGroups is
false, then the pivoting operation omits empty groups. If
IncludeEmptyGroups is true, then the pivoting operation
includes empty groups.
An empty group occurs when a possible value of a variable specified by
Columns or Rows is not represented in the input table,
such as in a categorical, logical, or binned numeric variable. For example, if no row in the
input table has a value of true for a logical grouping variable, then
true defines an empty group.
Example: P =
pivot(T,Columns="Var1",Rows="Var2",IncludeEmptyGroups=true)
RowLabelPlacement — Placement of row labels in the pivoted table
"variable" (default) | "rownames"
Placement of row labels in the pivoted table, specified as one of these values:
"variable"— Place row labels in the leftmost table variable of the pivoted table. IfRowsspecifies multiple grouping variables, place row labels in separate table variables."rownames"— Place the row labels to the left of the leftmost table variable. This option sets theRowNamesproperty of the pivoted table to the row group names. IfRowsspecifies multiple grouping variables, the pivoted table concatenates the group names with an underscore.
The row labels are defined by the group names in the grouping variables specified
by Rows.
Example: P =
pivot(T,Rows="Var1",RowLabelPlacement="rownames")
More About
Pivoting Operation
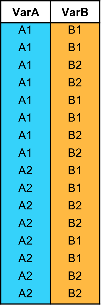
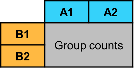
These tables illustrate pivoting operations.
Sample Table T | Syntax Example | Pivoted Table |
|---|---|---|
|
|
pivot(T,Columns="VarA",Rows="VarB") |
|
pivot(T,Columns=["VarA" "VarB"]) |
| |
pivot(T,Rows=["VarA" "VarB"]) |
|


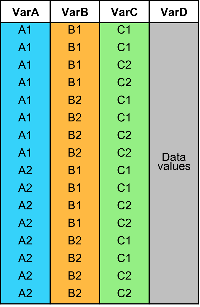
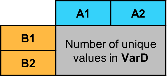
Sample Table T | Syntax Example | Pivoted Table |
|---|---|---|
|
|
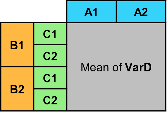
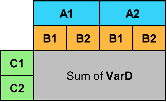
pivot(T,Columns="VarA",Rows="VarB",DataVariable="VarD",Method="numunique") |
|
pivot(T,Columns="VarA",Rows=["VarB" "VarC"],DataVariable="VarD",Method="mean") |
| |
pivot(T,Columns=["VarA" "VarB"],Rows="VarC",DataVariable="VarD",Method="sum") |
|
Tips
The
pivotfunction can apply the computation method to at most one data variable. To apply multiple computation methods or specify multiple data variables, use thegroupsummaryfunction.
Version History
Introduced in R2023aR2023b: Specify row names for pivoted table as row group names
You can now place row labels to the left of the leftmost table variable by setting the
RowLabelPlacement name-value argument to "rownames".
This option sets the RowNames property of the pivoted table to the row
group names. If Rows specifies multiple variables, the row labels are the
group names concatenated with an underscore. Previously, the pivoted table always placed row
labels in the leftmost table variables.
R2023b: Include empty groups in pivoting operation
Include, rather than omit, empty groups in the pivoting operation by setting the
IncludeEmptyGroups name-value argument to true. An
empty group occurs when a possible value of a variable specified by
Columns or Rows is not represented in the input
table, such as in a categorical, logical, or binned numeric variable.
See Also
Functions
groupsummary|groupcounts|unstack|findgroups|heatmap|bar3
Live Editor Tasks
Open Example
You have a modified version of this example. Do you want to open this example with your edits?
MATLAB Command
You clicked a link that corresponds to this MATLAB command:
Run the command by entering it in the MATLAB Command Window. Web browsers do not support MATLAB commands.
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: .
You can also select a web site from the following list:
How to Get Best Site Performance
Select the China site (in Chinese or English) for best site performance. Other bat365 country sites are not optimized for visits from your location.
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)