Using Machine Learning and Deep Learning for Energy Forecasting with MATLAB
Overview
AI, or Artificial Intelligence, is powering a massive shift in the roles that computers play in our personal and professional lives. Most technical organizations expect to gain or strengthen their competitive advantage of using AI. The AI workflows such as deep learning and machine learning are transforming industries with high impact. The power and Utilities industries are not exceptional from this AI mega trend. The legacy power grid is started adopting the concept of smart grid where the role of AI is crucial on multiple aspects. Grid analytics is one of key focus areas of the smart grid infrastructure, where load forecasting is highly pronounced. Forecasting the load on grid helps the power and utilities companies to plan their resources and effectively service the consumers demands in a profitable way. The medium-term forecasting and long-term forecasting are key focus of the energy production and utilities industry as it helps to decide on multiple strategies such as generation planning and demand side management services.
The load on the grid depends on multiple external factors making the data highly complex in nature. AI can be thought of as a tool to develop the forecast models for this complex data. At present, domain experts spend valuable efforts in cleaning data, searching for the right choice of predictive algorithms and fixing syntax of code. Manual deployment of developed models is also a cumbersome time-consuming process, and additionally requires IT expertise.
In this webinar, you will learn:
- How to leverage domain expertise in the AI workflow using MATLAB.
- How to deploy the algorithms seamlessly to the enterprise scale solutions.
About the Presenter
Recorded: 25 Aug 2020
Good morning. Welcome to the webinar on using machine learning and deep learning for energy forecasting with MATLAB. I am Jayanth Balaji, I am an application engineer here are bat365. Let us quickly deep dive into the topics that we have for today's discussion. In today's talk, we will learn what is load forecasting, who is benefiting by doing it, and why we need it. How to leverage your domain expertise in the AI workflow using MATLAB, and finally we will learn how to deploy the algorithms seamlessly to enterprise scale solution and integrate them with a dashboard.
Let us quickly jump into the first bucket for today's discussion on what is load forecasting and who will be benefiting by doing it? Why we need it? The [INAUDIBLE] is focused on the modernization, which is a megatrend seen in the recent years. When you think about the grid modernization the first and foremost thing that comes into play is renewable integration, which can be PV, wind turbine, and things like that. Due to the integration of renewables, there is a strong end requirement for energy storage because of both renewables and energy storage in the grid creates a lot of uncertainty in the grid operation.
Through the process of the entire grid, starting from generation, transmission, and all the way down to distribution, we generate terabytes of data in the deep cost of operation. And finally, the regulatory oversight comes into a picture of the entire power grid. The entire grid modernization can be conceptualized as almost smart grid, which primarily focuses on three area. One is power system studies and compliance study, grid analytics, and finally IoT and OT applications. As part of today's talk, we will be focusing more on grid analytics.
Grid analytics is a huge focus area which starts from asset management that will monitor the transformers and underground cables and things of same sort. We can develop the predictive maintenance algorithm, and we can estimate the remaining useful life of those assets. Similarly, you can think about accessing the grid stability and integrating the OSI PI with MATLAB, and doing some online analytics on top of the data, which we acquire from the field. We can also think about energy and price forecasting, but we can develop a [INAUDIBLE] algorithm to do the load forecasting and thinks of same sort. As part of today's talk, we will be focusing more on energy and price forecasting bucket.
Before getting into the actual topic for today's discussion, let us look into a user story from Fenosa where they predict energy of supply, demand. Using bat365 tools, they develop a flexible model, which can able to be updated and optimized based on their needs. And here are the results which Fenosa achieved. They reduced the response time by months, their productivity has doubled, and program maintenance is highly simplified.
Let us look into what is energy forecasting. Energy forecasting can be type of load forecasting, predicting load on the grid, or enable forecasting such as wind forecasting and solar forecasting, or it can be thought of price forecasting. Who need this particular energy forecasting is that starting from generation companies, [INAUDIBLE] power, all the way down to electricity consumers. As part of today's topic, we will be focusing more on load forecasting and how to do it in MATLAB, and what are the challenges, typically, comes when you think about load forecasting and how MATLAB comes in handy in those multiple case scenarios.
When we think about energy forecasting, even multiple utilities today, they are doing it manually. The energy forecasting workflow, which is done manually, is not scalable and not label in most of the cases. We can think AI as a tool to our trusty energy forecasting workflow and to make it more reliable and scalable. There are four buckets involved in AI-based workflow, starting from accessing, exploring the historical data, pre-processing the data, developing the forecast model with the help of machine learning and deep learning, and finally operationalize the models by deploying them into cloud or embedded systems.
There are multiple challenges associated with energy forecasting workflow starting from aggregating the data from multiple sources and handling the big data, cleaning the data and pre-processing it so that it is suitable for developing the forecast model, choosing a right forecast model from the number of forecast model that is available, and how to scale them into the production scale. Those are the typical challenges associated with energy forecasting workflow. Let us deep dive into each and every bucket on how MATLAB solves the challenges easily and helps you to do the task at a higher productivity.
In today's case study, we are going to develop machine learning and deep learning-based load forecasting algorithm to do the day ahead load forecasting. We are going to consider the New York ISO data set, which comprises of [INAUDIBLE] and feeder in it. We will develop the load forecasting algorithm in MATLAB. We will debug them, and make it suitable for deployment. We will deploy them into MATLAB production server, which is cost on Azure. We will integrate it with the third party dashboard and get the insight [INAUDIBLE].
When you think about the challenges associated, we have multiple challenges starting from data acquisition and pre-processing, finding the right set of forecasting technique, and scaling them to the cloud deployment. In big picture, we can-- finally, we are going to see how to integrate the developed algorithm into dashboard and get the insights, good visualization, of next day.
Let us look into each and every bucket of energy forecasting workflow starting from accessing data all the way down to operationalizing the models. Let us focus on the first bucket, accessing and exploring the data. These are the typical challenges associated with this particular bucket starting from getting the data from multiple sources, visualizing them. Let us look into MATLAB-based workflow for this particular bucket.
Before getting into this, this is a typical MATLAB window which comprises of current folder, workspace for the current working variables, command window where we will do the instant commands and testing, and this is a notebook which comprises of a text, which comprises of codes. We can add live task. Task is nothing but a GI-based workflow. We all know how life controls where we dynamically tune the particular input and get the results [INAUDIBLE]. Let us look into the first bucket, accessing and exploring the data.
I'm getting the historical data, as I mentioned, from New York ISO. I am downloading the historical data from website. I am unzipping and saving it for my further processing. Here I am [INAUDIBLE] using a data store, which is a pointer to your data, which handles the big data effectively on [INAUDIBLE] data challenges such as memory workflow and things like that. I am getting the raw data here. Let us look into the raw data. You can see that multiple figures are there, which is not properly organized. And there are a lot of zeroes in that.
Let us unstack them to get a better idea how one each and every figure looks like with the help of MATLAB command code unstack, prepare the command. I'm just unstacking the results. Now, I'm getting the better view of how the data looking for each and every figure. We also have a dedicated task based workflow for this unstack if we are not-- I am just using the one of the inbuilt tasks that is available in forms of tables and timetables bucket, which is nothing but unstacking of tables. I am just opening that.
Once you open the live task, it pop [INAUDIBLE] a GI window in the MATLAB. That we are going to select the table, which we want to unstack them. In our case, we are going to open the raw data set, which is nothing but nyiso raw. And I am selecting which will be the new name column and value column. Once I select that, MATLAB, in background, runs the program for me and gives me the similar result, which we didn't program that way. [INAUDIBLE] stop there, you will get the column code, whatever we do in form of task. So that there is nothing black box, we can understand what is happening behind the scenes and plan our things accordingly.
To make sure that is one and the same, I am just opening the table, which is table I've been using with task, which is nothing but the same table as we generated using a program [INAUDIBLE]. Let us quickly [INAUDIBLE] our signals to understand how well our data looks like, which gives an insight, also, that how our data points are there. I am going to use the stacked plot command, which is available in part of MATLAB predefined plotting command.
So I can see that plot off all the grids time. And just by visualizing, I can understand that there is some abnormalities in the data. Here, you can see that there are negative log conception, and there are multiple zero points in the data. By plotting what we understand here is that the data is not so clean and it requires a lot of preprocessing to be carried out.
I am just checking whether my data is the regular or equally sampled just with the [INAUDIBLE] concept called isregular command which is available in MATLAB, which gives me answer of zero, which means that my data is not regularly sampled. So we understood that a lot of abnormalities in the data in form of zero power consumption or negative log, and also the data, is not equally sampled or regularly sampled.
So coming back to the challenges, we start with this particular workflow. Starting from how to access the data from multiple sources, on how to visualize them, and we see that how MATLAB comes in handy in this particular bucket and solve the workflow at much of ease. So the challenges are normal challenges in this particular workflow. Let us look into the other buckets and discuss in detail.
Let us look into the next bucket, which is nothing but pre-processing and analyzing the data, which is one of the most difficult bucket in this entire workflow. It is a quote from Forbes, which says that 80% of the entire forecasting workflow, or the data analytics workflow, is spent on this particular bucket. And typical challenges associated with the workflow, starting from data aggregation from different sources, cleaning the data which is poorly formatted, irregularly sampled, and with redunadant and outliers. This typical bucket also has a problem with dealing out of memory problem, which we dealt earlier bucket as well.
Let us look into how MATLAB works in this particular bucket. When we think about pre-processing and analyzing the data, which can be sub-bucket into four workflows or four segments, starting from cleaning missing data, cleaning the outliers, smoothing the data, regularizing the timestamps. Earlier in our data visualizing, we have identified that our data suffers from a lot of zero entries, which is not a proper one. Here, we are going to use MATLAB live task, which is nothing but a GI-based workflow, to do the pre-processing bucket.
When you see here, we have multiple live task, especially in the data pre-processing bucket. We have clean missing, clean outlier, and smoothing of the data. I'm going to select one such task, which is nothing but clean missing data. What I'm going to do post-selecting is that I'm going to select the table which I want to clean. I'm selecting the input data, which is nothing but unstacked data. I'm selecting the variable in the table, which is nothing but one of the feeder unit. I am selecting a [INAUDIBLE] as a feeder unit here. I'm selecting the cleaning methods. And multiple interpolation techniques that are available to do this particular task, here you can see that.
I'm just selecting the linear interpolation. Once I save that linear interpolation, it automatically does the aurofilling of the missing entries. An advantage in autolearn stops here, we can able to see the innerlying code associated with this particular workflow. So there is nothing black box. We can deep dive into each of this code and understand better. And the next is nothing but cleaning the outliers. I'm going to use the similar workflow as we have a lot of spikes in our data. I'm going to use the one more live task, which is nothing but the clean outlier data task.
I'm going to import the previously cleaned the data, and I'm selecting the cleaning methods and suitable interpolation techniques. I'm specifying that threshold fact, which is nothing but the standard deviation. You can see, over here, dynamically the plot and the outlier is removed. You can appreciate that. However, it is easy to do with this task. Since my data is also susceptible to noise and have a lot of noise in the data I am going to smoothen it. I'm importing the outlier remove data, and I am selecting the smoothing parameter and smoothing method. Again, you we able to see the code, inner line code.
And as I mentioned in the previous bucket, our data is not equal sampled. We are going to use regularized timestamp. [INAUDIBLE] timing task that is available, again, in the live-- as part of live task. I'm going to import this method data. I am going to resample it for 30 minutes for my further processing. And here, I am getting the data. You can see here that it is equally sampled, now, for 30 minutes. I can see a lot of missing entries even here. I can able to fill that dynamically with the help of just clicking and pointing to the right filling methods. And again, I can able to visualize the inner line code of that.
You can appreciate how it is easy to do the pre-processing step with the help of MATLAB and its task. And there is nothing out of black box-- and there is nothing black box in it. You can understand the inner line code of it. The next step is I am going to aggregate the data since we know that load is depend upon the weather data also. I have done similarly cleans to really clean the weather data. I am loading it to clean the data. I am going to merge them together to create my predictors for my load forecasting workflow. I am just using the enable commands in commands to join them. We also have a dedicated task-based workflow which does the same job for you without doing any program, just by doing it interactively. And I am selecting the suitable joining mechanism over here. Once that is done, I am able to synchronize the two tables.
So this is done. Again, we are understanding inner line code of the [INAUDIBLE]. And I'm going to extract the predictors. So what I mean by predictors is that, fundamentally, we know that the load data depends upon multiple factors such as hour of the load conception, month of the load conception, and year of the load conception and things like that. So we are going to extract features from the data. We are going to extract features for our machine learning-based workflow. And we are also handling the time series data so that a sequence dependency exists in the workflow. So we are just plotting the correlation workflow-- correlation plot and understanding what is the typical pre-sequence to be considered for this particular time series forecasting.
So we have done that, and we understand that, typically, prior day is considered. And I'm generating the feature extractor to do my machine learning-based workflow. So you can think about it starting from a pre-processing step of cleaning the missing data all the way down to creating the flow. It's done in MATLAB and vary between very minimal programming knowledge. In a fraction of a minute, we can able to complete this particular workflow.
Let us look back into the challenges of this particular workflow, which we discussed earlier starting from data aggregation from different sources and cleaning the data effectively, and handling the big data. And as for the Forbes quote, we identify that this is one of the difficult bucket. By using MATLAB and its task, we have done the job very easily. You can appreciate that MATLAB-based workflow, how does the job effectively and easily for the entire workflow. For this particular workflow of a pre-processing and analyzing the data, the challenges are normal challenges. You easily adjust with help of MATLAB and its tools.
Let us look into the third bucket of the energy forecasting workflow, which is nothing but developing the forecast models. So when we think about developing the forecasting model, we can think about multiple techniques to address this. So we are going to focus on machine learning and deep learning-based workflow. Autofetch machine learning workflow requires feature extraction, which we did in previous step by extracting the predictors. And deep learning is nothing but a subset of machine learning, which doesn't require any feature extraction. It operates on pre-processed data.
When you think about typical challenges associated with this bucket, most of the people like us or lack data science expertise, and we don't know the right tool to solve the problem. And the required amount of time required for feature extraction, feature selection on model development of this particular workflow, is very difficult and time-consuming process. Let us look into the first bucket of this particular workflow, which is nothing but a machine learning-based workflow, and let us look into a MATLAB-based workflow. How it solves the entire process.
So a typical question arises within our mind is that, I am not a data scientist, how to develop an AI model for my workflow? For that, we have a dedicated app-based workflow inside MATLAB. When I look into the apps, we have multiple apps inside the machine learning and deep learning workflow. I am just selecting one such app, which just nothing but the regression learner. Since we have a task as a forecasting task, a regression-based task, I am just loading the data, which is a pre-processed data which we did in the earlier bucket. And I am selecting the response and predictor variable. Here, my response variable is nothing but a load and predictor table is the features, which we extracted in the previous step.
Since my data is time series data I am not selecting any validation, but you can select based on the sequences length you are considering. Once the data is loaded in this particular app, MATLAB automatically populates the rest of suitable algorithm for your workflow. So here, you can see that exhaustive set of algorithm that you can try it out starting from linear regression all the way down to ensemble trees. I'm going to try out all algorithm that is suitable for my data. I'm just pressing all and I'm enabling my parallel tool. I'm just-- I'm hitting the train model.
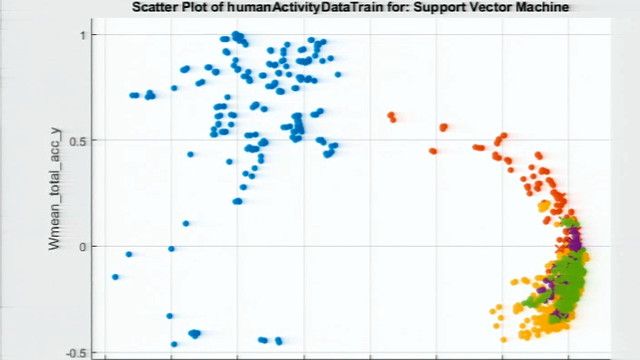
This is nothing but an AutoML concept. But we need to fill the data. Just everything will be taken care of by this particular app. There are 19 models in total in order which folder is running parallel. Because I have my quad formation. In a fraction of a minute, I can able to get a reasonable algorithm with reasonable forecasting accuracy, which is nothing but SVM I am getting for this particular data I got in minutes.
But I am not satisfied with my accuracy. MATLAB provides a capability to finetune this particular algorithm. I am selecting optimizable SVM since SVM is found to be suitable for my data. I am going and selecting the optimizable SVM. Once I select the optimizable SVM, I can able to select the hyperparameters I want to tune and type of optimizer, or type of optimizer which I want to try it on the actual hyperparameters in this particular workflow. I am selecting a bayesian optimizer, since it provides faster results.
I can also file select, which are the hyperparameters I want to tune starting from kernel functions and standard data. I am just selecting run again. So this will finetune the algorithm, which we got with reasonable accuracy in the earlier stage for the better accuracy. In fraction of minute, it's also got converged with the suitable hyperparameter for my data. The advantage in autolearn stops here. We can able to generate the function and we can understand what is happening inside for this particular workflow. And we can also export the model back to MATLAB workspace for the deployment. So machine learning is easily done with help of MATLAB.
But what if you don't have an idea to extract suitable features for your workflow? That is one of the crucial step in the machine learning-based workflow. So you can think about deep learning in that case. If you don't have enough domain expertise or even enough time to extract features from the data, you can think about deep learning. When you think about deep learning workflow, we are going to try out something different from the previous workflow. In the previous workflow, what we did is we try out individual models for individual feeder in the particular ISO. Here, we are going to play out unified modeling approach where a single model can able to address a multiple feeder at a time, and it can able to generate a forecast at time for all the feeders under consideration.
One quick change. What here we are doing is that we are splitting the data in form of seasons. This approach is applicable even for machine learning. Just to give an idea that it is applicable to all-- the one and all, I'm just trying it only for deep learning. I have split up the time initially. There our data after pre-processing. And since deep learning operates on normalized data, I just want to normalize the data. For that, I'm not doing anything. And I am generating diligent lag generation as we did in previous case. It is a prior data.
That said, we are not doing any feature extraction step in this particular workflow, deep learning-based workflow. We are going to use the same data for developing the deep learning models. So there are multiple techniques for developing deep learning, especially on time series data. So we are going to try out LSTM in this particular example, our particular case study. To solve the deep learning-based workflow, so again, we are going to use the app-based workflow. In particularly, especially on machine learning and deep learning bucket. We are going to use a deep network designer by which you can interactively generate the deep learning network.
So I am just using a particular app, which is nothing but a deep network designer. Once I open the app, you can able to see a lot of predefined algorithms are pre-trained network available for you. In this particular case, I am going to train the network from scratch. And I am pulling out the event layer suitable for my workflow, in this case, sequence input layer. I see SSL, I am going to try out LSTM this particular example. I am going to pull out LSTM layer. Just to start with, I am pulling out two LSTM layers. Then I'm going to connect fully connected layer. Then I am going to add the integration layer at the output layer.
Post-selecting the suitable layers, I'm just making the connection between the layers just by tagging and clicking. This particular app allows you to interactively chain the input and output parameters. In our case, we are having 528 inputs and 528 outputs. I am just manually doing it. And this app also comes with analyzer, which analyzes the network for error. In this particular case, I don't have any error. It also gives an idea how input travels from input to output layers and different learnables associated with this particular network.
Post-analyzing, I can export back the network to MATLAB for training with initial parameters or just the network. I just exported back the network in MATLAB, you can see that the entire network is built in form of like an app-based workflow. This is the same network I have copied here. I am specifying detaining options, which is nothing but hyperparameters. And I'm going to train the network. It help a command called trainNetwork construct available in MATLAB. I feed the input, output layers and options. And I'm just saving the network in the name of net dot spring.
This is a training graph. And I obtained 400 epochs, which gives the input and starting time, and estimate time, or elapsed time. I added similarly for all the seasons, and I obtained the network. You can appreciate how the deep network [INAUDIBLE] helped in this particular workflow of generating the deep network. I want to try out multiple experiments that is on the hyperparameters of this particular network. In this particular network, the hyperparameters are nothing but the multiple options. You can try out-- to try out multiple experiments on the network and comparing the best of the [INAUDIBLE] for our workflow. You have a dedicated workflow called experiment manager.
But I want to create a new project for comparing my experiments and select the best hyperparameter for my workflow. I am just planned to set my experiments on my initial learning grid and my epochs for training. Once I set this experiment, I can go ahead and run my experiments on my developer network in the previous stage. So I'm going to just run the experiment on my network. You can see that the experiment is running on my network, and this is a snapshot of a completed experiments or completed workflow.
There, you can see that multiple experiments are on the same networks with multiple combinations of learning rate and epochs, and their autumn season losses are plotted over here. We can select the best work suitable for our workflow. And we can export a particular network back to MATLAB for the next stage, which is nothing but the deployment. I can filter it out, I can select deep suitable network based on my choice, and I can export back to MATLAB.
[INAUDIBLE] or a trade-off before going into like a machine learning or deep learning. Here, how to make a choice whether you want to try out deep learning or machine learning. We exhaustively support both of these workflows. Based on your domain knowledge and data sense-- data set availability, you can make a choice whether you want to go ahead with deep learning or machine learning. We also support intermittent workflow, that we extract some features to assist the deep learning in form of time frequency map or pre-processing. We also support them exhaustively inside MATLAB. We can try out multiple things. And this is a great-- we'll give you an idea how to choose the choice of algorithm for my workflow. So it depends upon data set size versus domain knowledge versus compute resource you have.
Let us look into the final bucket of the energy forecasting workflow, which is nothing but operationalizing model. We have developed the forecast model in the previous bucket, and now we want to deploy them to the-- deploy them to the cloud or embedded hardware for operationalizing them. So let us look into a quick chart, our quick workflow chart, which gives an idea of what we can do once the model is developed in the MATLAB. We have multiple products aligned to support the operationalizing model. We can think about a coder-based workflow. If you want to deploy the end algorithm and embedded hardware using the coder product, you can able to generate the C, C++, HDL, PLC, and coder-targeted codes.
Using the compiler-based workflow, you can able to generate the standalone executables like exes. You can generate Excel add-ins. You can also try out MATLAB webapp and webapp, by which you can host the app in your browser. We also have MATLAB Compiler SDK, by which you can able to generate the shared library package, such as C, C++, Java, Python, and .NET. This comes in handy if you have a larger system which is already developed in these packages and you want to integrate this particular energy forecasting with MATLAB. You can [INAUDIBLE] to generate the shared library and you can integrate with the existing system.
We also support cloud-based deployment with help of MATLAB production server. There we can hold-- there which can-- where MATLAB production server can host multiple MATLAB algorithms on cloud-based platforms. When you think about the challenges, there are multiple challenges associated with this particular bucket starting from how to scale the app and how to deploy them. Traditionally, people do the manual translation, of course. And the end user can be highly varying in nature, starting from operators onto all the way to customers. So there are multiple targets, which will [INAUDIBLE] target platform. So we have all the way from cloud to embedded hardware.
So there are multiple challenges associated with this particular workflow. Let us look into quick demonstration with help of MATLAB how to solve these challenges. We have a MATLAB function, which in nothing but the forecast model, which we did-- which we created in the earlier workflow. We have multiple workflow. Then we are going to-- we use the inbuilt app, which is nothing but a MATLAB production server compiler which comes as part of application deployment app. I am going to select the MATLAB production server compiler by which we can be able to generate the cloud executable.
I'm just opening the function. This app is very intelligent enough to understand the prerequisite automatically. So in this particular app comprises of all the predefined models to be used in this particular deployment. It automatically recognized that. I'm just testing the client before posting it on the actual cloud. And I am selecting the MATLAB and functional MATLAB breakpoint errors. And I am just now starting the client. It's just nothing but the MATLAB app is hosted on this particular endpoint. And I'm going to write a few lines of code which is already available in MATLAB documentation to pass the workflow.
So I'm just placing a web write on this particular endpoint. The endpoint is nothing but local host in the port number followed by a MATLAB function. I'm just placing a web write, which is nothing but an API call. Once a press n, can able to see that the request is placed on the local host. That status is pending. Once execution is completed, the status change to complete, I will get the insight. This is a debugging platform which allows us to make our algorithm error-free. We can thoroughly test it before deploying into the end cloud platform.
I'm going to package the cloud executable. I'll generate the executable, cloud [INAUDIBLE] which is nothing but a CTF, which is compile target format. [INAUDIBLE] select this particular workflow. It comes with a readme file, which discuss about the steps and procedure we can follow for deployment. As I said earlier, I am going to deploy it on Azure platform where a MATLAB production service is hosted to run the MATLAB algorithms. I'm just uploading the application, which is nothing but the application which is centered on the [INAUDIBLE]-- with their MATLAB production server compiler. And I am selecting the deploy. It's deployed on this particular endpoint. So I'm going to use the same endpoint to place my EPA calls and get the results.
So in the same testing code I'm going to use, only thing is that I'm going to change the local host to the Azure endpoint. I am verifying whether I am getting the proper insight. I'm exactly getting the same thing. Now, the next step is we are going to integrate with the dashboard. Here, we are going to try out Power BI dashboard. We have MATLAB connector to support inside Power BI dashboard for connecting with the MATLAB production server. But I want to specify the endpoints, function name, and file name. And you can able to see that I am getting the-- I am placing the query from MATLAB-- I'm placing the query from Power BI. I am getting the insights and the follow-up table [INAUDIBLE], which comprises of all [INAUDIBLE] feeders.
All [INAUDIBLE] feeders in this particular network, [INAUDIBLE] particular [INAUDIBLE]. And I am getting the normalized power consumption value for next 24 hours. The same thing I'm going to try out with the other dashboards. I'm going to try out with the post Power BI dashboard. I'm following the same thing, same procedure. I'm placing an API call to the same MATLAB productions our endpoint. Here, I'm entirely selecting the particular feeder in the map. And the load for next 24 hours is generated. I'm going to try it one more thing, like with JavaScript-based dashboard. This end point remain one and the same. And I'm generating the forecast for next 24 hours. You can appreciate that how it is easily generated.
So we started with challenges, with where we want to host it on cloud-based platform and we need a manual translation. But here, everything is in scene-- but the scenery changes with help of MATLAB. So MATLAB solved these challenges easily with help of inbuilt app associated with the workflow. And you can appreciate that how it is easily doable in MATLAB.
In summary, MATLAB helps you to solve the energy forecasting problem at ease starting from data aggregation all the way to scaling up to the production level. You can appreciate that how MATLAB and its inbuilt apps and task-based workflow solve the entire workflow process at ease. And here are the key takeaways for this particular webinar. So when you think about MATLAB as a workflow and MATLAB as a tool for your workflow, the pre-processing is no more a time-consuming process.
We here spend a minimal amount of effort of this particular bucket. And MATLAB enables the domain expert to do data science. You don't need to be a data science expert to do the AI-based task in MATLAB. We have an [INAUDIBLE] framework and where you can use the app-based workflow. MATLAB automatically does the data science job for you. And MATLAB analytics can turn on anyway, starting from embedded hardware to cloud deployment. One and the same algorithm can turn on multiple platforms with the help of quadrant compiler products. You can think about MATLAB as a platform rather than a tool to solve your workflow.
To advance your skill in MATLAB and Simulink, we have multiple courses associated-- training courses associated with MATLAB and Simulink. For data science, we have multiple courses starting from Onramp courses, which is a short two [INAUDIBLE] courses. You'll get it for free. You can able to do the machine learning-- you can able to learn MATLAB, machine learning, and deep learning-based workflow. We also have MOOC-based courses hosted on Coursera in the title of practical data science with MATLAB specialization.
We also offer bat365 customized training for data science. If you need customized training for your organization, please reach out at training at bat365 We have a consulting service by which you can accelerate your entire process where our consultants will be supporting your workflow. And you can think about bat365 as your engineering partner to do the [INAUDIBLE] task. And that's all I have for today. Thank you.
Featured Product
Deep Learning Toolbox


Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: .
You can also select a web site from the following list
How to Get Best Site Performance
Select the China site (in Chinese or English) for best site performance. Other bat365 country sites are not optimized for visits from your location.
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
- 中国
- 日本Japanese (日本語)
- 한국Korean (한국어)