Analyze Japanese Text Data
This example shows how to import, prepare, and analyze Japanese text data using a topic model.
Japanese text data can be large and can contain lots of noise that negatively affects statistical analysis. For example, the text data can contain the following:
Variations in word forms. For example, "難しい" ("is difficult") and "難しかった" ("was difficult")
Words that add noise. For example, stop words such as "あそこ" ("over there"), "あたり" ("around"), and "あちら" ("there")
Punctuation and special characters
These word clouds illustrate word frequency analysis applied to some raw text data from "吾輩は猫である" by 夏目漱石, and a preprocessed version of the same text data.

This example first shows how to import and prepare Japanese text data, and then it shows how to analyze the text data using a Latent Dirichlet Allocation (LDA) model. An LDA model is a topic model that discovers underlying topics in a collection of documents and infers the word probabilities in topics.
Import Data
Load the example data "factoryReportsJP.csv". The data contains factory reports, including a text description and categorical labels for each event in Japanese. Read the table using the readtable function and extract the text as strings. Assign the names "Var1", "Var2", ..., "Var5" to the table variables by setting the ReadVariableNames option to false.
filename = "factoryReportsJP.csv"; data = readtable(filename,"TextType","string","ReadVariableNames",false);
View the first few rows of the table. The table contains these variables:
Var1— DescriptionVar2— CategoryVar3— UrgencyVar4— ResolutionVar5— Cost
Extract the text data from the variable Var1 and view the first few reports.
textData = data.Var1; textData(1:10)
ans = 10×1 string
"スキャナーのスプールにアイテムが詰まることがある。"
"アセンブラのピストンからガタガタと大きな音がします。"
"工場起動時に電源が切れる。"
"アセンブラのコンデンサが飛ぶ。"
"ミキサーでヒューズが切れる。"
"コンストラクション・エージェントのパイプが破裂して冷却水を噴射している。"
"ミキサーでヒューズが飛んだ。"
"ベルトから物が続々と落ちてきます。"
"ベルトから物が落下する。"
"スキャナーのリールが割れている、すぐにカーブし始める。"
Visualize the text data in a word cloud.
figure wordcloud(textData);

Tokenize Documents
Tokenize the text using tokenizedDocument and view the first few documents.
documents = tokenizedDocument(textData); documents(1:10)
ans =
10×1 tokenizedDocument:
11 tokens: スキャナー の スプール に アイテム が 詰まる こと が ある 。
12 tokens: アセンブラ の ピストン から ガタガタ と 大きな 音 が し ます 。
8 tokens: 工場 起動 時 に 電源 が 切れる 。
6 tokens: アセンブラ の コンデンサ が 飛ぶ 。
6 tokens: ミキサー で ヒューズ が 切れる 。
17 tokens: コンストラクション ・ エージェント の パイプ が 破裂 し て 冷却 水 を 噴射 し て いる 。
7 tokens: ミキサー で ヒューズ が 飛ん だ 。
11 tokens: ベルト から 物 が 続々 と 落ち て き ます 。
7 tokens: ベルト から 物 が 落下 する 。
14 tokens: スキャナー の リール が 割れ て いる 、 すぐ に カーブ し 始める 。
Get Part-of-Speech Tags
Get the token details and then view the details of the first few tokens.
tdetails = tokenDetails(documents); head(tdetails)
ans=8×8 table
Token DocumentNumber LineNumber Type Language PartOfSpeech Lemma Entity
___________ ______________ __________ _______ ________ ____________ ___________ __________
"スキャナー" 1 1 letters ja noun "スキャナー" non-entity
"の" 1 1 letters ja adposition "の" non-entity
"スプール" 1 1 letters ja noun "スプール" non-entity
"に" 1 1 letters ja adposition "に" non-entity
"アイテム" 1 1 letters ja noun "アイテム" non-entity
"が" 1 1 letters ja adposition "が" non-entity
"詰まる" 1 1 letters ja verb "詰まる" non-entity
"こと" 1 1 letters ja noun "こと" non-entity
The PartOfSpeech variable in the table contains the part-of-speech tags of the tokens. Create word clouds of all the nouns and adjectives, respectively.
figure idx = tdetails.PartOfSpeech == "noun"; tokens = tdetails.Token(idx); subplot(1,2,1) wordcloud(tokens); title("Nouns") idx = tdetails.PartOfSpeech == "adjective"; tokens = tdetails.Token(idx); subplot(1,2,2) wc = wordcloud(tokens); title("Adjectives")

Prepare Text Data for Analysis
Remove the stop words.
documents = removeStopWords(documents); documents(1:10)
ans =
10×1 tokenizedDocument:
5 tokens: スキャナー スプール アイテム 詰まる 。
6 tokens: アセンブラ ピストン ガタガタ 大きな 音 。
5 tokens: 工場 起動 電源 切れる 。
4 tokens: アセンブラ コンデンサ 飛ぶ 。
4 tokens: ミキサー ヒューズ 切れる 。
8 tokens: コンストラクション ・ エージェント パイプ 破裂 冷却 噴射 。
4 tokens: ミキサー ヒューズ 飛ん 。
6 tokens: ベルト 物 続々 落ち き 。
4 tokens: ベルト 物 落下 。
8 tokens: スキャナー リール 割れ 、 すぐ カーブ 始める 。
Erase the punctuation.
documents = erasePunctuation(documents); documents(1:10)
ans =
10×1 tokenizedDocument:
4 tokens: スキャナー スプール アイテム 詰まる
5 tokens: アセンブラ ピストン ガタガタ 大きな 音
4 tokens: 工場 起動 電源 切れる
3 tokens: アセンブラ コンデンサ 飛ぶ
3 tokens: ミキサー ヒューズ 切れる
6 tokens: コンストラクション エージェント パイプ 破裂 冷却 噴射
3 tokens: ミキサー ヒューズ 飛ん
5 tokens: ベルト 物 続々 落ち き
3 tokens: ベルト 物 落下
6 tokens: スキャナー リール 割れ すぐ カーブ 始める
Lemmatize the text using normalizeWords.
documents = normalizeWords(documents); documents(1:10)
ans =
10×1 tokenizedDocument:
4 tokens: スキャナー スプール アイテム 詰まる
5 tokens: アセンブラ ピストン ガタガタ 大きな 音
4 tokens: 工場 起動 電源 切れる
3 tokens: アセンブラ コンデンサ 飛ぶ
3 tokens: ミキサー ヒューズ 切れる
6 tokens: コンストラクション エージェント パイプ 破裂 冷却 噴射
3 tokens: ミキサー ヒューズ 飛ぶ
5 tokens: ベルト 物 続々 落ちる くる
3 tokens: ベルト 物 落下
6 tokens: スキャナー リール 割れる すぐ カーブ 始める
Some preprocessing steps, such as removing stop words and erasing punctuation, return empty documents. Remove the empty documents using the removeEmptyDocuments function.
documents = removeEmptyDocuments(documents);
Create Preprocessing Function
Creating a function that performs preprocessing can be useful to prepare different collections of text data in the same way. For example, you can use a function to preprocess new data using the same steps as the training data.
Create a function which tokenizes and preprocesses the text data to use for analysis. The function preprocessText, performs these steps:
Tokenize the text using
tokenizedDocument.Erase punctuation using
erasePunctuation.Remove a list of stop words (such as "あそこ", "あたり", and "あちら") using
removeStopWords.Lemmatize the words using
normalizeWords.
Remove the empty documents after preprocessing using the removeEmptyDocuments function. Removing documents after using a preprocessing function makes it easier to remove corresponding data such as labels from other sources.
In this example, use the preprocessing function preprocessText, listed at the end of the example, to prepare the text data.
documents = preprocessText(textData); documents(1:5)
ans =
5×1 tokenizedDocument:
4 tokens: スキャナー スプール アイテム 詰まる
5 tokens: アセンブラ ピストン ガタガタ 大きな 音
4 tokens: 工場 起動 電源 切れる
3 tokens: アセンブラ コンデンサ 飛ぶ
3 tokens: ミキサー ヒューズ 切れる
Remove the empty documents.
documents = removeEmptyDocuments(documents);
Fit Topic Model
Fit a latent Dirichlet allocation (LDA) topic model to the data. An LDA model discovers underlying topics in a collection of documents and infers word probabilities in topics.
To fit an LDA model to the data, you first must create a bag-of-words model. A bag-of-words model (also known as a term-frequency counter) records the number of times that words appear in each document of a collection. Create a bag-of-words model using bagOfWords.
bag = bagOfWords(documents);
Remove the empty documents from the bag-of-words model.
bag = removeEmptyDocuments(bag);
Fit an LDA model with seven topics using fitlda. To suppress the verbose output, set 'Verbose' to 0.
numTopics = 7;
mdl = fitlda(bag,numTopics,"Verbose",0);Visualize the first four topics using word clouds.
figure for i = 1:4 subplot(2,2,i) wordcloud(mdl,i); title("Topic " + i) end

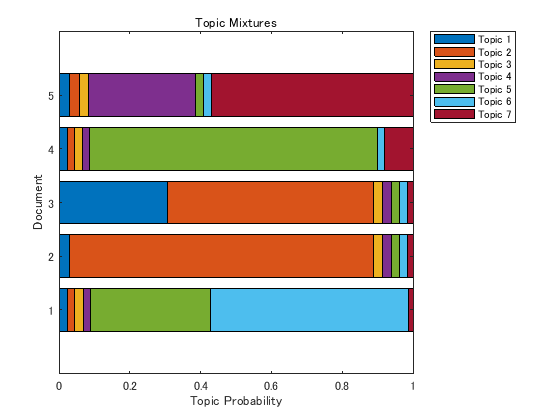
Visualize multiple topic mixtures using stacked bar charts. View five input documents at random and visualize the corresponding topic mixtures.
numDocuments = numel(documents); idx = randperm(numDocuments,5); documents(idx)
ans =
5×1 tokenizedDocument:
4 tokens: ミキサー 激しい 揺れる 音
3 tokens: ベルト 物 落下
3 tokens: コンベア ベルト 詰まる
4 tokens: ミキサー 冷却 あちこち こぼれる
3 tokens: トランスポート ライン 動く
topicMixtures = transform(mdl,documents(idx)); figure barh(topicMixtures(1:5,:),"stacked") xlim([0 1]) title("Topic Mixtures") xlabel("Topic Probability") ylabel("Document") legend("Topic " + string(1:numTopics),"Location","northeastoutside")
Example Preprocessing Function
The function preprocessText, performs these steps:
Tokenize the text using
tokenizedDocument.Erase punctuation using
erasePunctuation.Remove a list of stop words (such as "あそこ", "あたり", and "あちら") using
removeStopWords.Lemmatize the words using
normalizeWords.
function documents = preprocessText(textData) % Tokenize the text. documents = tokenizedDocument(textData); % Erase the punctuation. documents = erasePunctuation(documents); % Remove a list of stop words. documents = removeStopWords(documents); % Lemmatize the words. documents = normalizeWords(documents,"Style","lemma"); end
See Also
tokenizedDocument | removeStopWords | stopWords | addPartOfSpeechDetails | tokenDetails | normalizeWords
Related Topics
- Language Considerations
- Create Simple Text Model for Classification
- Analyze Text Data Using Topic Models
- Analyze Text Data Using Multiword Phrases
- Analyze Text Data Containing Emojis
- Train a Sentiment Classifier
- Classify Text Data Using Deep Learning
- Generate Text Using Deep Learning (Deep Learning Toolbox)
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)