Data Cleaner
Open the Data Cleaner App
MATLAB Toolstrip: On the Apps tab, under MATLAB, click the app icon.
MATLAB command prompt: Enter
dataCleaner.
Examples
Import and Clean Timetable Data
Use the Data Cleaner app to preprocess and organize messy timetable data by removing a variable and retiming, smoothing, and normalizing the data. Then, export the cleaned data to the MATLAB workspace. You can follow these steps to preprocess and organize messy timetable data, but note that your data may require a different set of cleaning steps.
This example shows how to preprocess and organize time-stamped bicycle traffic data. The data set comes from sensors on Broadway Street in Cambridge, MA. The City of Cambridge provides public access to the full data set at the Cambridge Open Data site.
Open Timetable in Data Cleaner App
Use the MATLAB Toolstrip or the MATLAB command window to open the Data Cleaner app.
Load the time-stamped bicycle traffic data by using
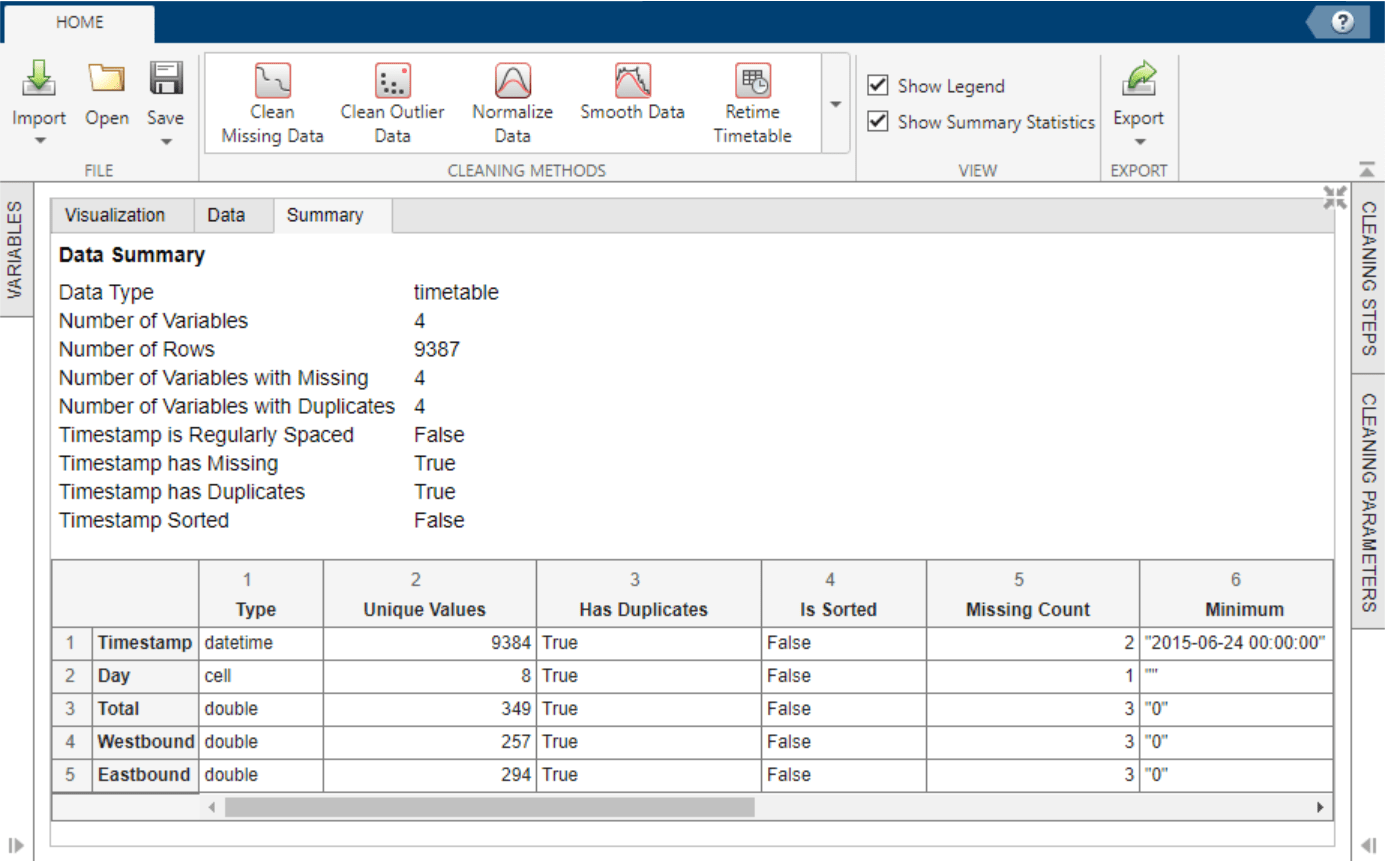
bikeData = readtimetable("BicycleCounts.csv")in the command window. Then, select Import > Import from Workspace in the Data Cleaner app, and specify the timetablebikeData. Alternatively, import the data by selecting Import > Import from File in the Data Cleaner app.Once the timetable is loaded into the app, view the raw data in the Data tab and a data summary in the Summary tab.
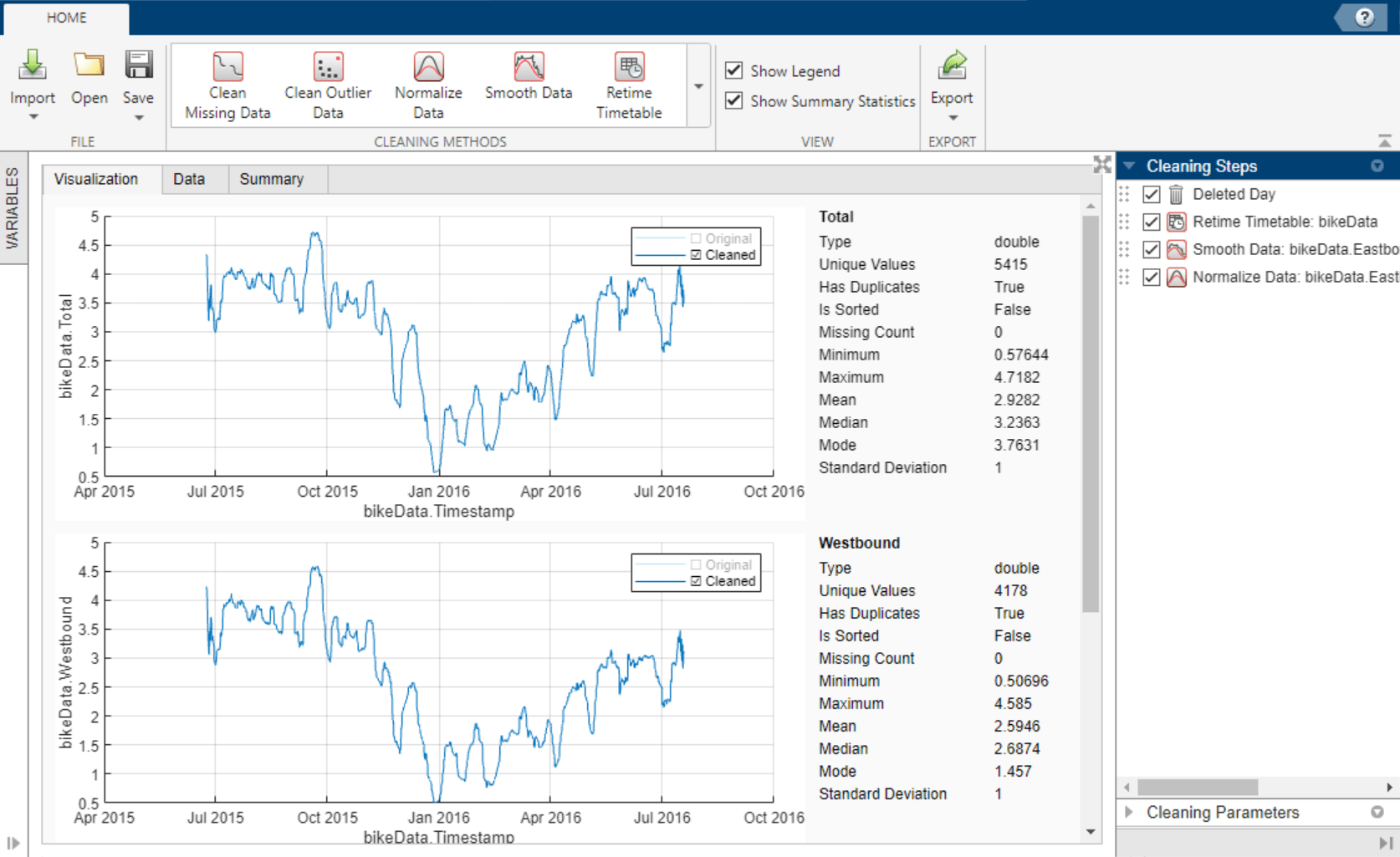
Explore the timetable data in the Visualization tab. Select the
Total,Westbound, andEastboundtimetable variables in the Variables panel.The plots suggest that there is a correlation between time of the year and bike traffic.
Remove Variable from Timetable
The
Dayvariable contains redundant data because the day of data collection is reflected in the timestamp. Interactively removeDayfrom the timetable by using the Variables panel. To remove the variable, right-clickDayand select Delete. Variable removal now appears as a step in the Cleaning Steps panel.Retime Timetable
The data summary shows missing and duplicate timestamp values in the timetable. To sort the timetable and establish unique row times, click Retime Timetable in the Cleaning Methods section of the Home tab of the app. Specify
Unique row times of inputas the selection method and use theSummethod to aggregate. Accept the cleaning parameters to add the cleaning step and update the timetable.After accepting the retiming parameters, the updated data summary shows that there are no missing or duplicate timestamp values and that the timestamps are sorted from earliest to latest.
If retiming is not necessary for your timetable, you can interactively sort by
Timestampor another timetable variable. Access the sorting options by clicking the arrow in the variable header in the Data tab.
in the variable header in the Data tab.Smooth Data
Because the bicycle traffic spikes for certain days of each week, smoothing can lessen the noise within each week and give better insight into the bicycle traffic trend throughout the year. To smooth the data, use the Smooth Data cleaning method. Select the
Moving meansmoothing method and specify a centered 7-day window for smoothing. Accept the cleaning parameters to add the cleaning step and update the timetable.Normalize Data
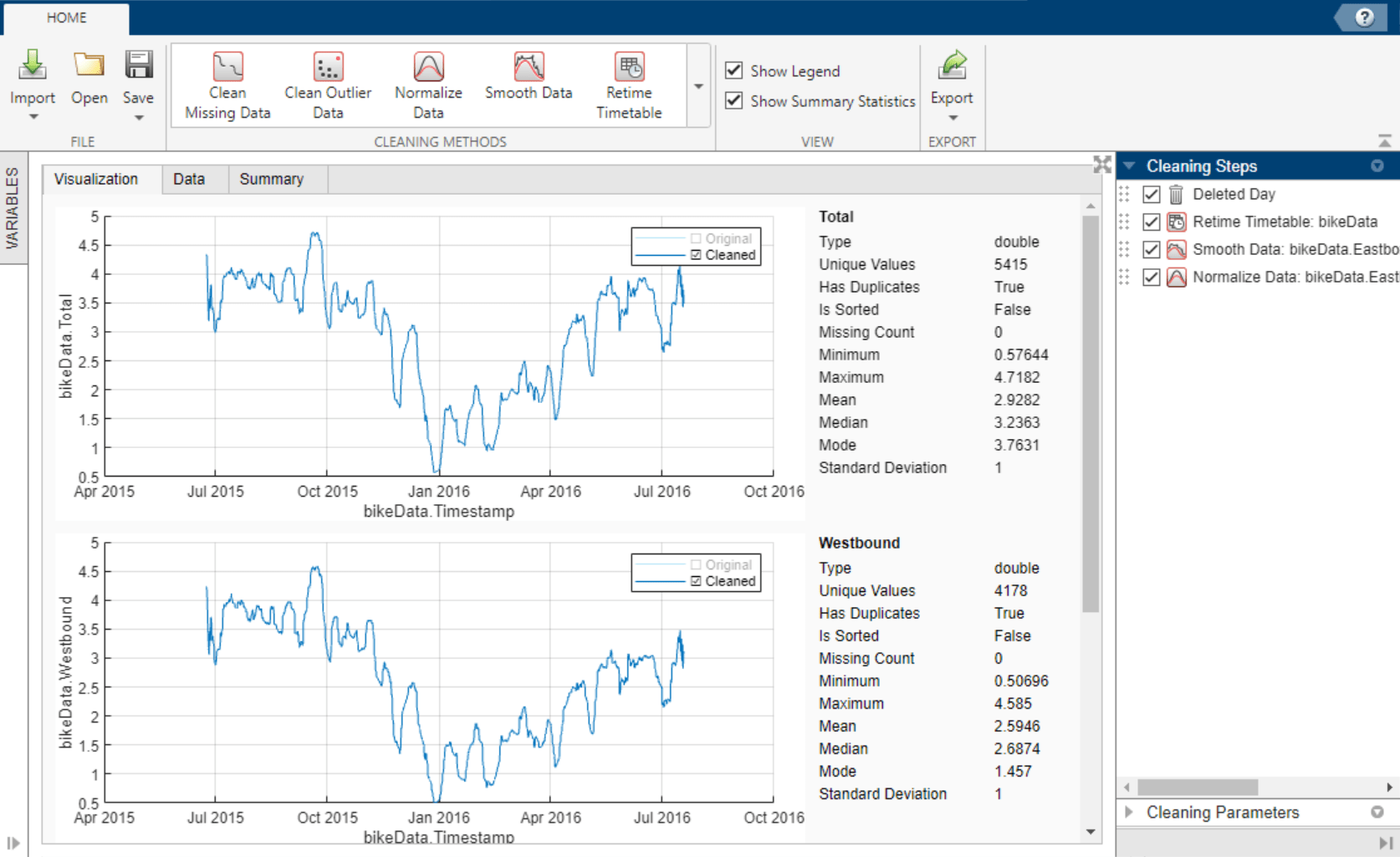
Because the three numeric variables
Total,Westbound, andEastboundhave different scales, use normalization to scale by standard deviation. To normalize the data, use the Normalize Data cleaning method. SelectScaleas the normalization method andStandard deviationas the scale type.To more clearly preview this cleaning step, clear the original data in the legend of the visualizations. Accept the cleaning parameters to add the cleaning step and update the timetable.
Export Timetable
Export the cleaned timetable to the MATLAB workspace by selecting Export > Export to Workspace.
Alternatively, export timetable cleaning code by selecting Export > Generate Script or Export > Generate Function.
Parameters
Tips
To interactively sort by a data variable, access the sorting options by clicking the arrow
in the variable header in the Data tab. The
sorting appears as a step in the Cleaning Steps panel.To interactively rename a variable from the data, double-click the variable name in the Variables panel. The renaming appears as a step in the Cleaning Steps panel.
To interactively remove a variable from the data, right-click the variable name in the Variables panel and select Delete. The removal appears as a step in the Cleaning Steps panel.
To alter previously performed cleaning steps, perform one of these actions:
View or edit cleaning parameters by clicking a step in the Cleaning Steps panel.
Change the order in which cleaning steps are performed by dragging a step to a new location in the Cleaning Steps panel.
Disable cleaning steps by clearing a cleaning step or right-clicking a step and selecting Disable Steps Below in the Cleaning Steps panel.
To view only the input data or cleaned data, select or clear elements in the plot legends in the Visualizations tab.
Version History
Introduced in R2022aSee Also
Live Editor Tasks
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)