GPU Programming Paradigm
GPU-accelerated computing follows a heterogeneous programming model. Highly parallelizable portions of the software application are mapped into kernels that execute on the physically separate GPU device, while the remainder of the sequential code still runs on the CPU. Each kernel is allocated several workers or threads, which are organized in blocks and grids. Every thread within the kernel executes concurrently with respect to each other.
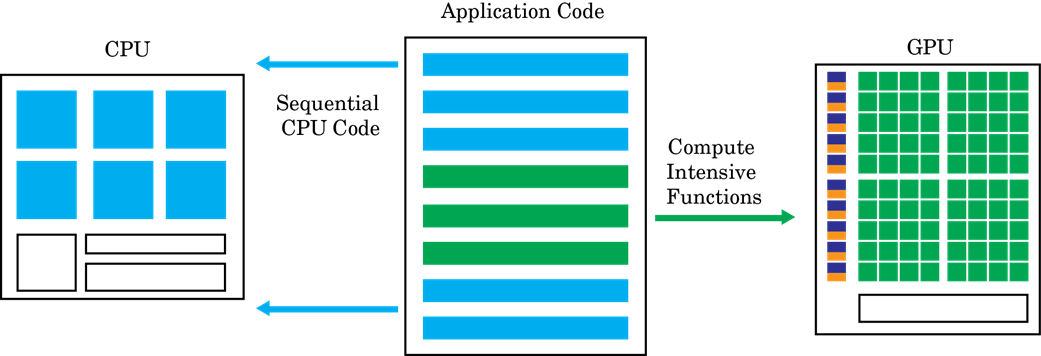
The objective of GPU Coder™ is to take a sequential MATLAB® program and generate partitioned, optimized CUDA® code from it. This process involves:
CPU/GPU partitioning — Identifying segments of code that run on the CPU and segments that run on the GPU. For the different ways GPU Coder identifies CUDA kernels, see Kernel Creation. Memory transfer costs between CPU and GPU are a significant consideration in the kernel creation algorithm.
After kernel partitioning is complete, GPU Coder analyzes the data dependency between the CPU and GPU partitions. Data that is shared between the CPU and GPU are allocated on GPU memory (by using
cudaMallocorcudaMallocManagedAPIs). The analysis also determines the minimum set of locations where data has to be copied between CPU and GPU by usingcudaMemcpy. If using Unified Memory in CUDA, then the same analysis pass also determines the minimum locations in the code wherecudaDeviceSynccalls must be inserted to get the right functional behavior.Next, within each kernel, GPU Coder can choose to map data to shared memory or constant memory. If used wisely, these memories are part of the GPU memory hierarchy structure and can potentially result in greater memory bandwidth. For information on how GPU Coder chooses to map to shared memory, see Stencil Processing. For information on how GPU Coder chooses to map to constant memory, see
coder.gpu.constantMemory.Once partitioning and memory allocation and transfer statements are in place, GPU Coder generates CUDA code that follows the partitioning and memory allocation decisions. The generated source code can be compiled into a MEX target to be called from within MATLAB or into a shared library to be integrated with an external project. For information, see Code Generation Using the Command Line Interface.
Related Topics
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)